非常感谢。
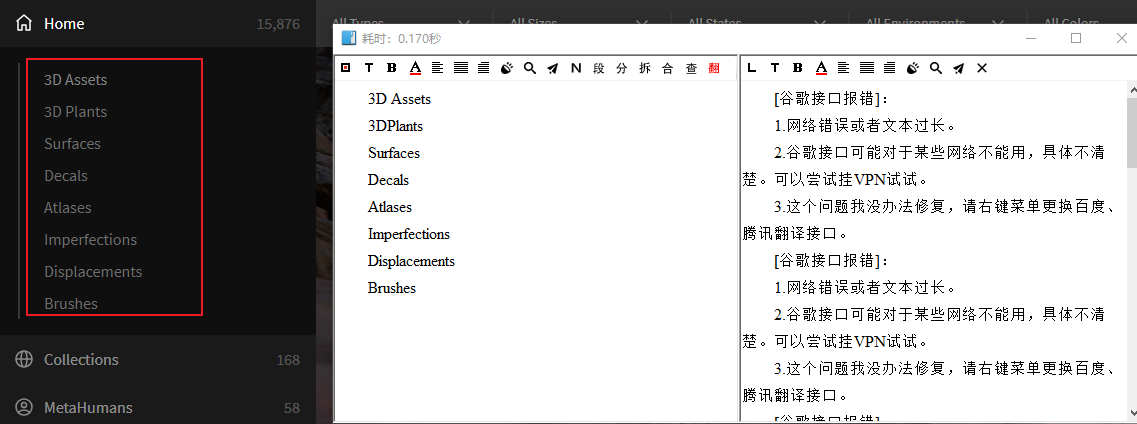
应该是ip被封了,尝试更换线路以后可以使用了,非常感谢。
我也刚用1.2.4 翻译正常哦
订阅贴 特意表示支持一下
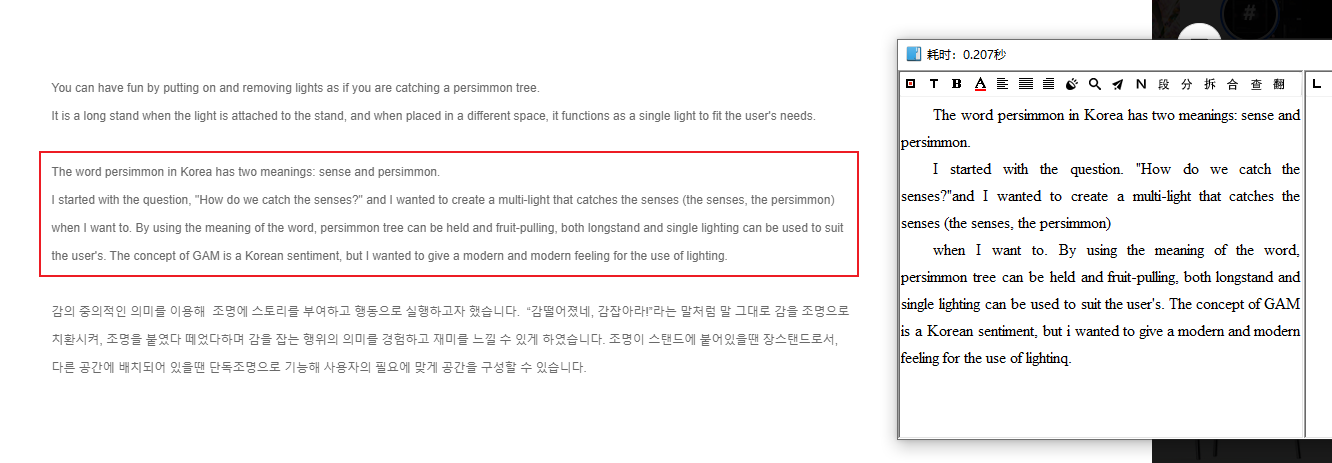
这张是天若5.0原版的百度ocr识别出来的结果,段落结构是非常清晰的,与原始文本一致。

这张是本地 Paddle ocr 的结果,本身段落及句子完整性较差。
请问是否会考虑增加百度ocr的接口供用户选择?
哈哈,我做本地接口是因为百度的ocr给的次数太少了,现在看来本地ocr对于英文真是一塌糊涂,等过几天我再把百度ocr加进来。
如果有很强的需要,你可以考虑下天若ocr官方的,我当初测试本地ocr是中文识别舒服,英文主要因为空格存在很难受
感谢回复,我的使用场景英文ocr再译中会比较多,所以这样的情况下英文ocr的质量其实特别重要。像您说的,本地ocr中文识别做的还是非常好的。
其实我并没有特别专业的需求,比如表格识别公式识别之类的,所以之前的5.0开源版对我来讲非常实用方便,所以我的诉求基本上就是复活5.0版的谷歌翻译功能就行。
再次感谢您所做的工作。
链接: 百度网盘-链接不存在 提取码: itak 复制这段内容后打开百度网盘手机App,操作更方便哦
你好,由于我自己的百度api过期了,请帮我测试一下,接口选择百度
我换了自己申请的 可以用的
好的,谢谢测试
大佬 Deepl那个翻译挺精准的,能加进去吗?
不行,deel并不开放接口给大陆,网页爬取的话效果也不行,基本上没几个翻译软件带deel的
尝试启动v1.2.5版本单文件程序时报以下错误(也尝试了124版,同样):
System.IO.FileNotFoundException: 未能加载文件或程序集“OcrLib, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null”或它的某一个依赖项。系统找不到指定的文件。
文件名:“OcrLib, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null”
在 TrOCR.FmMain..ctor()
在 TrOCR.Program.Main(String[] args)
环境是 64位 win10 + .NET 4.8
不知是否有能够帮助解决的头绪?
你好,并没有单文件的版本 ![]() ,我发布的是一个替换文件,你需要下载之前的压缩包,比如1.2.2版本,然后把最新的替换进去
,我发布的是一个替换文件,你需要下载之前的压缩包,比如1.2.2版本,然后把最新的替换进去
1 个赞
OK,明白了。不过如果您能在替换版本的备注里提上一句就更好了,我就是v125不好使之后想到了这个可能性,然后跑去v124一看,嚯也是单文件的,于是就没多想……
总之非常感谢。
确实表述不清楚,多谢提醒
1 个赞