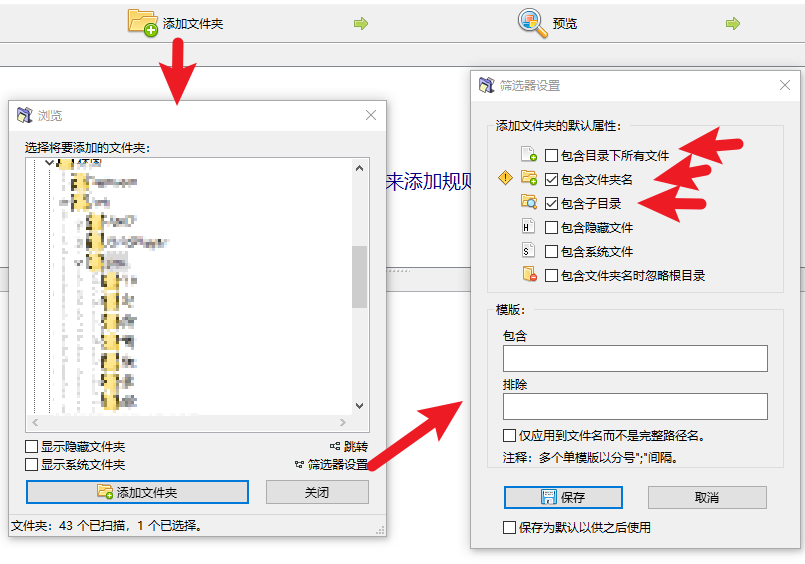
花了半小时粗糙的写了个,注意下规则,只判断文件名,规则里不要带除了*外正则支持的字符
https://wwz.lanzout.com/iPrYx1o6jgqd
import os
import re
import natsort
import send2trash
rule_file = '规则.txt'
def get_all_paths(folder: str):
"""提取文件夹下所有的文件路径和文件夹路径"""
filepaths_join = [] # 文件路径
dirpaths_join = [] # 文件夹路径
if os.path.exists(folder) and os.path.isdir(folder):
for dirpath, dirnames, filenames in os.walk(folder):
for j in filenames:
filepaths_join.append(os.path.normpath(os.path.join(dirpath, j)))
for k in dirnames:
dirpaths_join.append(os.path.normpath(os.path.join(dirpath, k)))
return filepaths_join, dirpaths_join
else:
return None, None
def join_paths(filepaths: list, dirpaths: list):
"""将文件路径和文件夹路径合并为一个dict,key为父目录路径,value为父目录下的文件/文件夹路径"""
paths_join = filepaths + dirpaths
dir_dict = dict()
for i in paths_join:
parent_folder = os.path.split(i)[0]
if parent_folder not in dir_dict:
dir_dict[parent_folder] = []
dir_dict[parent_folder].append(i)
# 按路径从长到短排序key
keys = list(dir_dict.keys())
keys_sorted = natsort.natsorted(keys, alg=natsort.ns.PATH, reverse=True)
dir_dict_sorted = {key: dir_dict[key] for key in keys_sorted}
return dir_dict_sorted
def read_rules():
"""读取规则,并转换为正则格式"""
try:
with open(rule_file, 'r', encoding='utf-8') as f:
rules = f.readlines()
except UnicodeDecodeError:
with open(rule_file, 'r') as f:
rules = f.readlines()
rules_re = []
for rule in rules:
rule = rule.strip('\n')
rule = rule.replace('*', '.*') # 替换字符
rule = '^' + rule + '$' # 添加正则的起始和结束标识
rules_re.append(rule)
print(rules_re)
return rules_re
def check_rule_file():
"""检查规则文件是否存在"""
if not os.path.exists(rule_file):
with open(rule_file, 'w', encoding='utf-8'):
pass
def is_filename_format(filename: str, rules_re):
"""检查文件名是否符合规则"""
for rule in rules_re:
if re.match(rule, filename, flags=re.IGNORECASE):
return True
return False
def get_filename(path):
"""提取文件名"""
if os.path.isdir(path):
return os.path.split(path)[1]
else:
return os.path.split(os.path.splitext(path)[0])[1]
def check_format(dir_dict: dict, rules_re):
"""检查是否符合规则"""
delete_paths = []
for parent_folder, paths in dir_dict.items():
parent_folder_filename = get_filename(parent_folder)
if is_filename_format(parent_folder_filename, rules_re): # 文件夹符合规则,内部全部文件符合规则才进行处理
temp_delete = []
for path in paths:
if os.path.isfile(path): # 仅处理文件
filename = get_filename(path)
if is_filename_format(filename, rules_re):
temp_delete.append(path)
if len(temp_delete) == len(paths):
delete_paths.extend(paths)
else: # 文件夹不符合规则,则直接处理内部文件
for path in paths:
if os.path.isfile(path): # 仅处理文件
filename = get_filename(path)
if is_filename_format(filename, rules_re):
delete_paths.append(path)
return delete_paths
def delete_files(files: list):
"""删除文件"""
for i in files:
send2trash.send2trash(i)
print('已删除文件:', i)
def delete_empty_dirs(dir_dict: dict):
"""删除空文件夹"""
for dir_ in dir_dict.keys():
if os.path.exists(dir_) and len(os.listdir(dir_)) == 0:
send2trash.send2trash(dir_)
print('已删除空文件夹:', dir_)
def show_files(files):
"""显示预删除文件"""
print('符合规则的文件如下:')
for i in files:
print(i)
print(f'------共{len(files)}个文件------')
def main():
print('--维护好"规则.txt"后,再输入需要检查的文件夹路径--')
print('--记得看规则说明--')
while True:
check_rule_file()
dirpath = input('输入需要检查的文件夹路径:')
if not os.path.exists(dirpath) or os.path.isfile(dirpath):
print('输入路径有误,请重新输入!')
continue
filepaths, dirpaths = get_all_paths(dirpath) # 获取路径
dir_dict = join_paths(filepaths, dirpaths) # 整合路径
rules_re = read_rules()
delete_paths = check_format(dir_dict, rules_re) # 获得符合规则需要删除的文件路径
show_files(delete_paths)
if len(delete_paths) != 0:
makesure = input('是否执行删除(至回收站)?(y/n)')
if makesure.upper() == 'Y':
delete_files(delete_paths)
delete_empty_dirs(dir_dict)
if __name__ == '__main__':
main()