朱邦復做的六代衹有不超過五碼的規定。
工作室都把碼錶放出來了,不止12345,到9都有,就是用來避重的。
你這個不就是無理補碼嗎,很多輸入法都有,但是別人至少會設計一套有理,沒人拿無理補碼來宣傳避重。
朱邦復做的六代衹有不超過五碼的規定。
工作室都把碼錶放出來了,不止12345,到9都有,就是用來避重的。
你這個不就是無理補碼嗎,很多輸入法都有,但是別人至少會設計一套有理,沒人拿無理補碼來宣傳避重。
唔,看了半天,感觉你可以把自己的输入方案(或者称为“选字方案”?)发出来,这样大家也好直接对比一下啊,我光看到了你说你的输入方案优越,但确实没能找到你发的方案啊 ![]()
而郑码、五笔啥的都是网上已有的资料,可以很方便地进行查证,空口无凭地说终究还是缺了点说服力
(万一你也能依托仓颉开创一个小众的“绝对无重”流派呢是吧[注,我也没想好怎么形容这个“绝对无重”该怎么进一步地使其表意更加清晰])
想不明白追求绝对无重码的意义在哪里?
常用汉字 3500 字,规范汉字才 8000 多字。保证这些字的无重码才有意义。
生僻字、罕见字,可能一年还输入不了两次,就这两次,选一下字很耗时间吗?
如果是为了无重码,而对常见字做了妥协,那这种无重码不要也罢。
有几个人讲话全是大段文字,啊啊啊,实在读不下去,能不能每次提炼个 TL;DR 出来,再给内容加一些小标题。现在已经在怀疑究竟是我理解能力有问题还是你们表达能力有问题了。
只有仓颉能做你也应该把适合仓颉的配置发出来啊,不发出来只是说大家谁能真正理解呢?
就好像我说有个开源的编程语言,效率碾压C,安全远超Rust,简单远胜Python,还有一大堆数据做支撑,结果就是不告诉你他的名字和具体的开源地址,这谁能信啊……
所以说还是请尽快发一下配置比较好,这样也能让大家做出判断
二编:论坛确实无法发送过大的文件,但这不是有github吗?再不济也可以用腾讯文档,金山文档等等在线文字编辑软件啊
论坛有ai总结 ![]()
由于在简中网页上可以方便地搜索到郑码的相关教程,因此我认为他们“没给”是可以理解的,繁中确实不清楚能否便捷地搜索到相关教程。
现在我想问您要一下您自己的详细配置可以吗,哪怕它仅能用于仓颉输入法,确实是很好奇是否真的有一种办法能够做到5码内绝对无重并且符合汉字结构逻辑
郑码教材及相关资料如下:
https://www.china-e.com.cn/li/main/zhengma/xz-1.htm
抱歉,我确实没能在官网找到“绝对无重”或者其他表示类似意思的段落
69 条回复中你的回复占据了 34 条,@CCR 的内容你用连续的三层楼回复。你觉得我该怎么处理一下呢?
如果你不能精炼内容,提升表述能力,我觉得读不下去的时候将会按照垃圾信息处理。(此为第一次正式警告![]()
那您可以另开一贴,在本帖下讨论有偏题之嫌。
无论它是否属于具体的“取码规则”,如果您希望对此进行详细讨论,那么应该全部发出了才对,理论必须用实践来验证。
举例,基于rime的雾凇配置给出了详尽的配置文件,哪怕它是对核心几乎没有影响的“小”配置文件,也应当应发尽发,以利于网友讨论
推荐宇码输入法,两岸三地简繁全字集极低选重,无障碍输入。欢迎加群研讨:735728797
需要祭出杀器 Talk is cheap 了吗……
如果极大段辩经才能表明你的意思,通常意味你想说明的不是一个实体而是某种概念。所以,我不礼貌地请楼上的 @apaqiu:stop talking, just show me the fxxking code (config)!
Throw a link in my face 也比辩经好啊…
很抱歉,正如您所说,仓颉官方是没有提供码表的,而截至目前我也仍然没能看到你说的“这个码表”在哪里能方便地找到,而郑码的相关资料已经发送给您,此外,网络上也有其他人列举的码表可用。
同上,无链接
所以我是否能理解为,你的按“Z”本质上等同于抬头看了一眼屏幕,确定了要选的字是哪个,然后根据候选项按了数字键?您的按z是否本质上和下面那段伪代码发挥的作用基本一致呢?实际上也是通过多次按“Z”键达到了按数字键选字的效果。
int i = 1;
when ("z".pressed == true) {
i = i + 1;
}
send(i);
在我看来,这方面的讨论就是偏题。
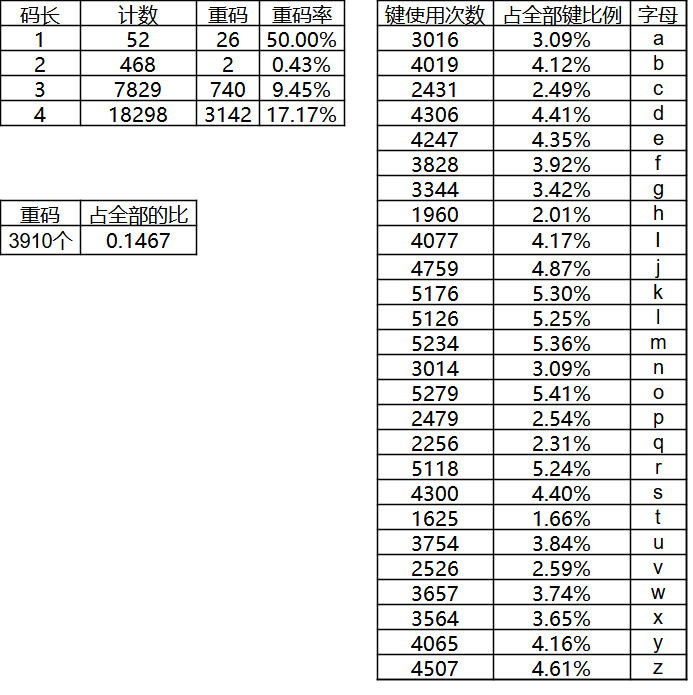
既然话都说到这里了,另附一份您要的郑码码表及我个人的统计在此(注,为2015年版本)。
郑码统计信息如下:
https://www.jianguoyun.com/p/DbN8G2YQoKLBChj_qboFIAA
很遗憾,您的猜想是错误的,并且错的很离谱
最后一次警告,讨论时请给出足够让大家能清晰明白知晓的具体证据,而非只说车轱辘话。如果您始终无法给出相应的证据,那么您将被禁言。