http://211.103.242.133:8080/ziyuan/CDDPdf/dis/20111125/产科/
上面的网页本身不能访问,但是该【产科】目录下面的文件可以下载,还被Google收录,如:
http://211.103.242.133:8080/ziyuan/CDDPdf/dis/20111125/产科/妊娠剧吐.pdf
请教各位大佬,我想下载该目录下的所有文件,该如何操作?谢谢~
http://211.103.242.133:8080/ziyuan/CDDPdf/dis/20111125/产科/
上面的网页本身不能访问,但是该【产科】目录下面的文件可以下载,还被Google收录,如:
http://211.103.242.133:8080/ziyuan/CDDPdf/dis/20111125/产科/妊娠剧吐.pdf
请教各位大佬,我想下载该目录下的所有文件,该如何操作?谢谢~
应该不行吧,除非能想办法找到索引,要不把网站黑了得到文件列表?
这个问题有点像ftp里没有list权限,又想根据一个文件地址来下载其他文件
可以试试暴力枚举?
http://211.103.242.133:8080
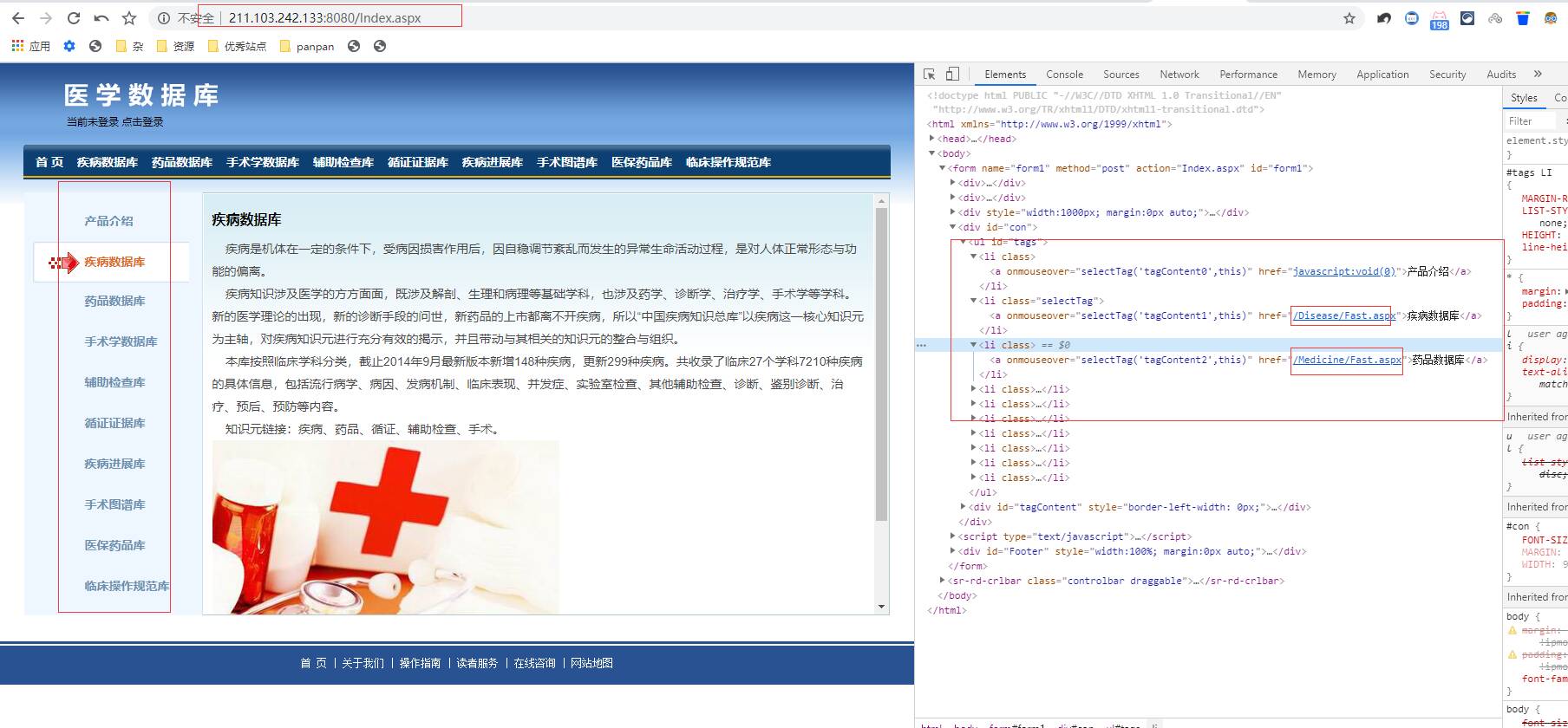
直接访问这个页面 疾病数据库 找到你要的科室 有能下载的地方 这里你就自由发挥吧
是爬虫还是怎么 自己搞吧 我没这技术
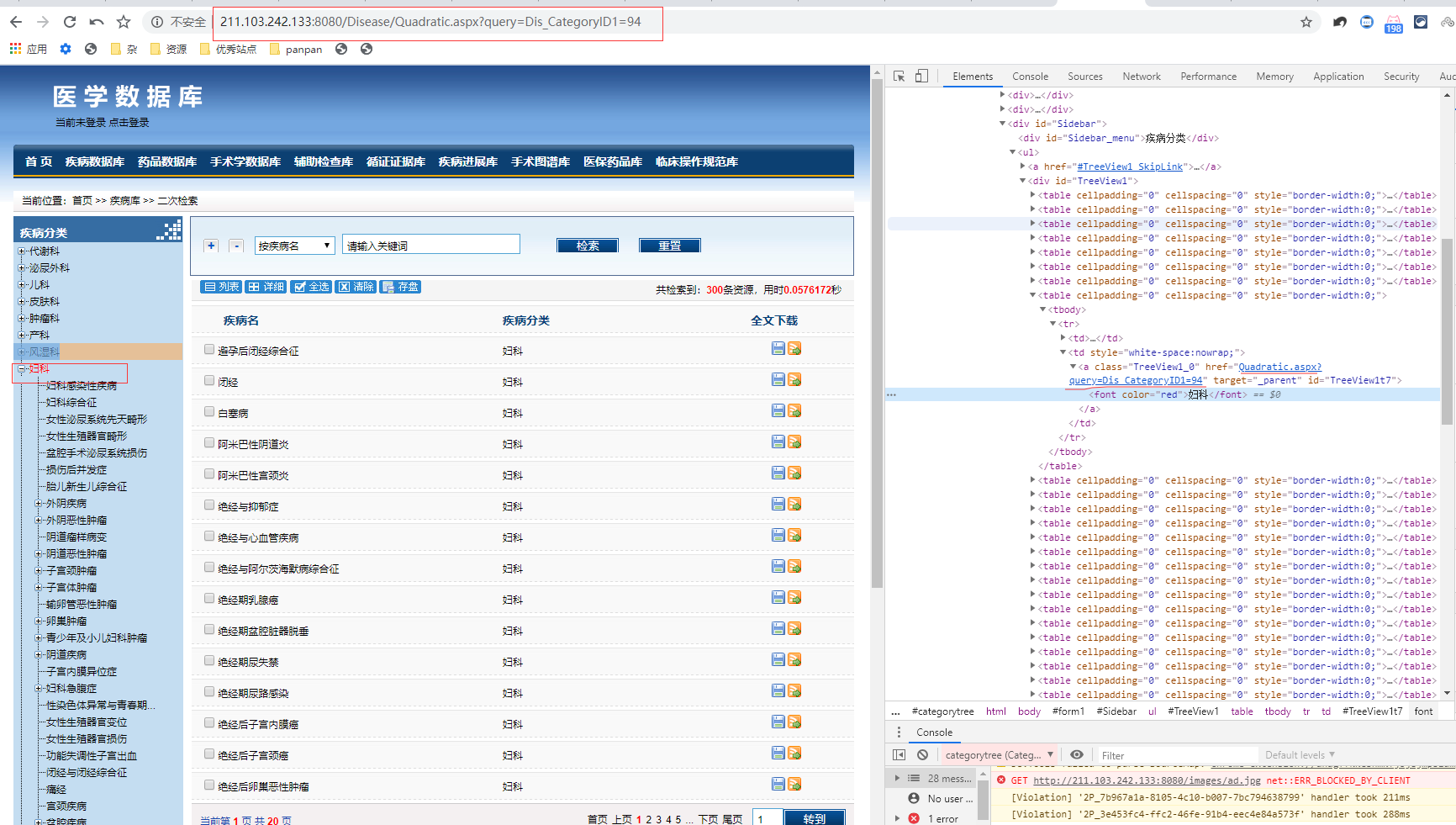
这个 索引 可以通过前面的网站,查询到名称,但是他的翻页是JS控制,不好爬。。。而且,有的疾病没有对应的下载文件。。。
20111125 /产科/妊娠剧吐.pdfGoogle 收录了的话,就用 Google 好了。应该如果网站上有链接到的文件都会有,孤立文件就不好说了。
但二百多个结果应该可以让楼主满意吧。
你说的该目录是哪一层目录?
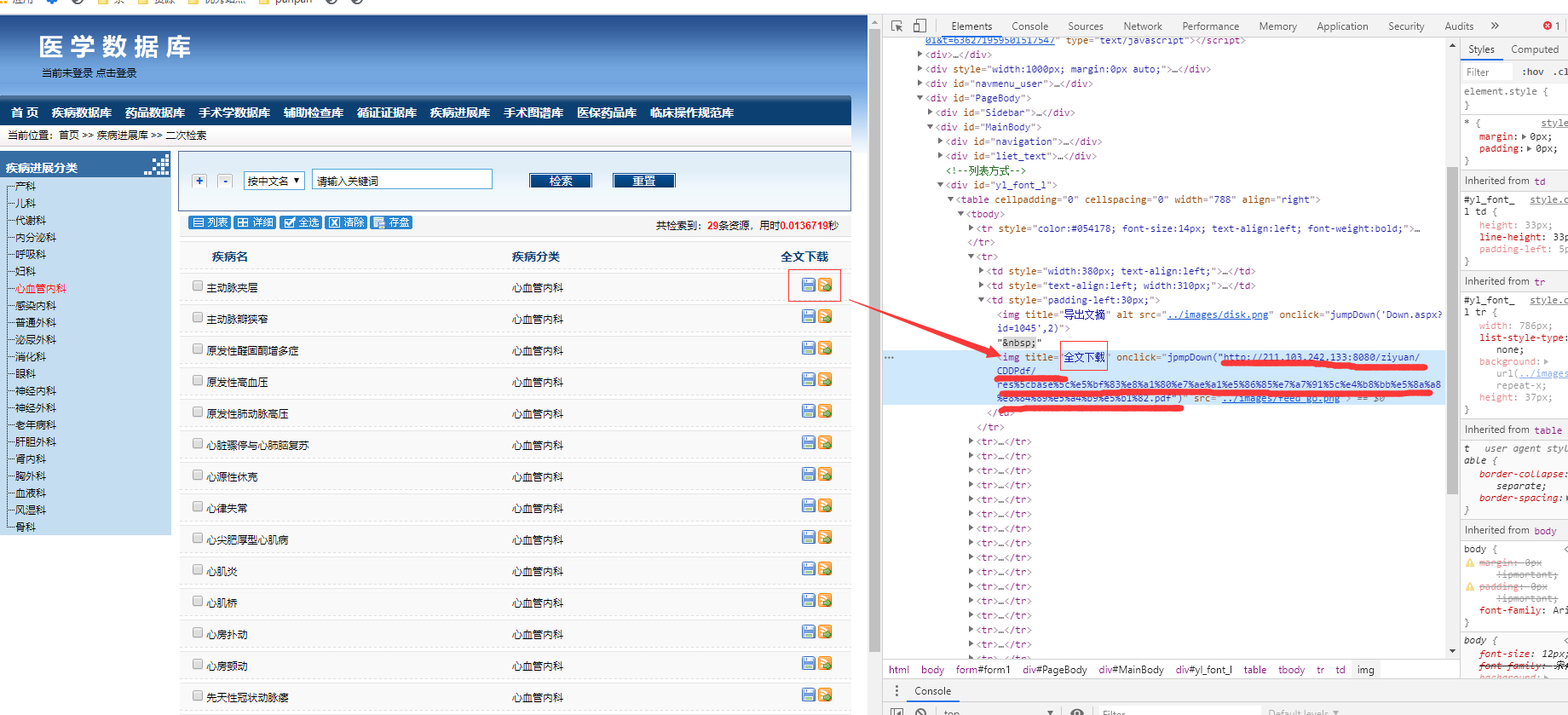
小哥哥,步骤四是干嘛用的?看不懂
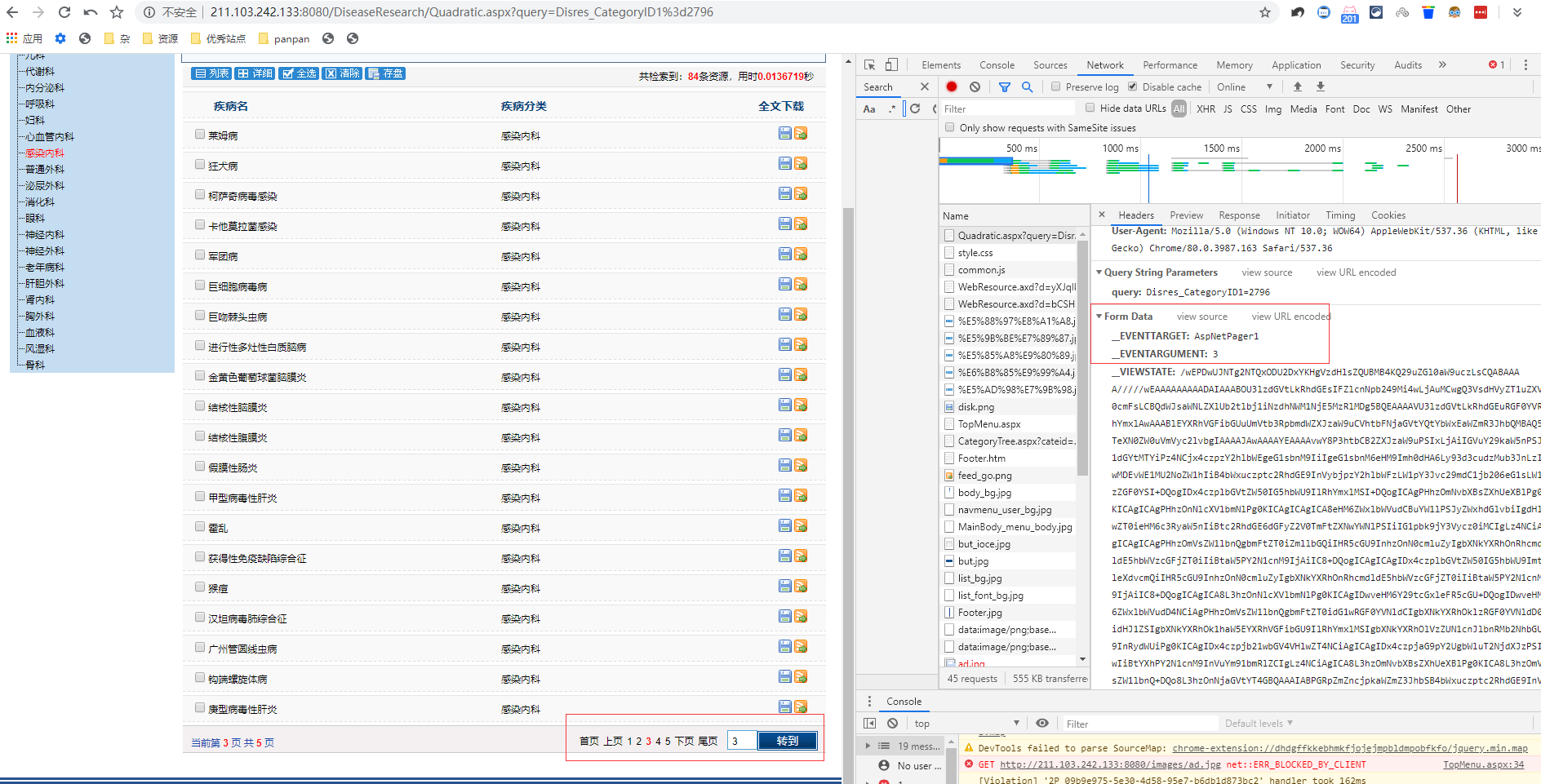
步骤4是页面翻页请求,其中两个关键参数我圈出来了,注意是有cookie的,这个需要写爬虫的时候测一下请求页面翻页数据,我看到这懒得试了大概原理就这样,试试看就知道了
could you please elaborate?
可是Google是怎么能索引到的?
Google 不全,应该只收集了,这两个地址的,
但是还有一些病不在这2个地址下:比如 妊娠合并炎性肠病(在第9页)
我觉得可以从20111125穷举到 20140930 ,要是没结果,我觉得可能就 没希望了
google是根据外部url索引的啊.不是通过枚举目录.
外部url索引? 我也可以吗? ![]()