这个时候要不要去试试chatgpt ![]()
感谢!感觉这种需求实在是太小众了,为此专门开发工具不值当也产生不了价值。没有现成的工具或方案,就不整理了,乱就乱吧。
或许可行,但我不是搞机器学习的,以后可能会学习点皮毛,但为了现在这个小需求,不值得投入太多时间和精力。
非常感谢!完美解决问题![]()
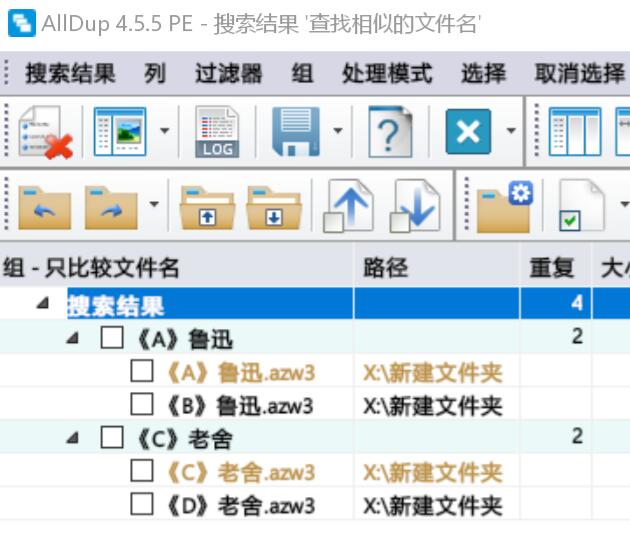
我使用alldup对模拟数据做了一个测试,结果怎么说呢…只能说alldup很强,但在这个问题上并不能“完美”解决问题,仍然留有少许遗憾。
如图:
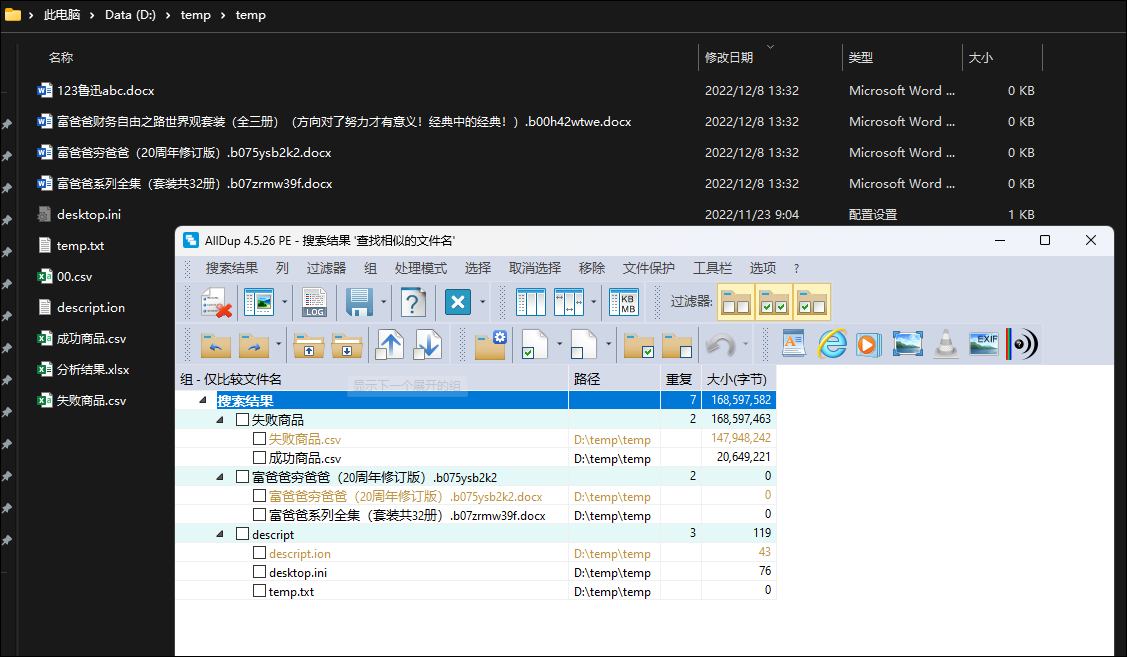
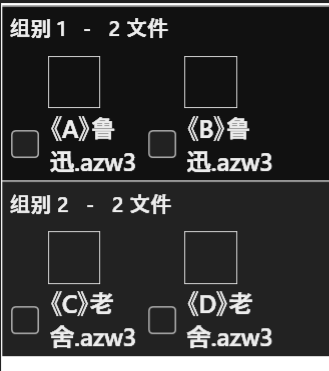
仅摘取“富爸爸”系列3个文件,选择fuzzy match模式,将匹配率降低到20%,仍然无法完整匹配三个文件。从这里看,我估计alldup采用的是文本相似度匹配原理,而不是分词后的词频聚类方法。相信在实际应用过程中,其结果要么是匹配率较高而匹配不到,要么是匹配率较低乱匹配。
想看看楼主实际应用效果反馈是怎样的。
在参数没变的条件下,我最开始选了一套同系列的书籍进行测试,结果都匹配到了。您回复后,又测试了富爸爸系列,结果11本匹配到10本。刚才对所有书进行了匹配,结果全乱了,没有任何规律,和您猜想的一样。
我暂时不整理了,太耗费时,后续就关注豆瓣读书推荐,看哪本搜哪本吧。
话说,突然想起来我电脑里也存了一个
找不到整理的办法,一直在那扔着。。。。。。
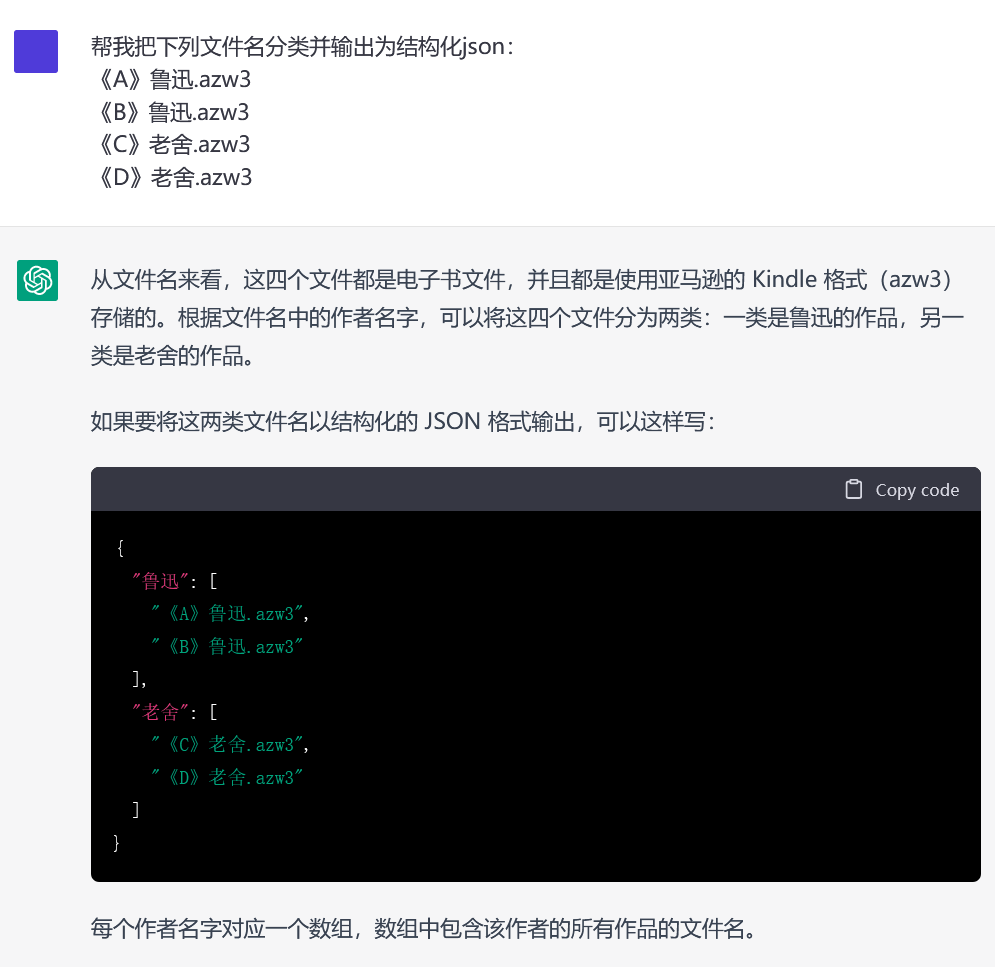
厉害哦,试试这个:
老舍《A》.azw3
《B》老舍著.azw3
《C》老舍.azw3
《D》by鲁迅.azw3
《鲁迅合集》.azw3
《F》周树人.azw3
我也想玩,可是没号
仅考虑搜索的话,这类模糊搜索能一路扯到 语义向量检索 这方向上去
但从目的出发,楼主是不是更该找个支持刮削的图书管理软件
https://gpt.chatapi.art/ 这个不需要登录,直接用
1 个赞
厉害哦,这都行
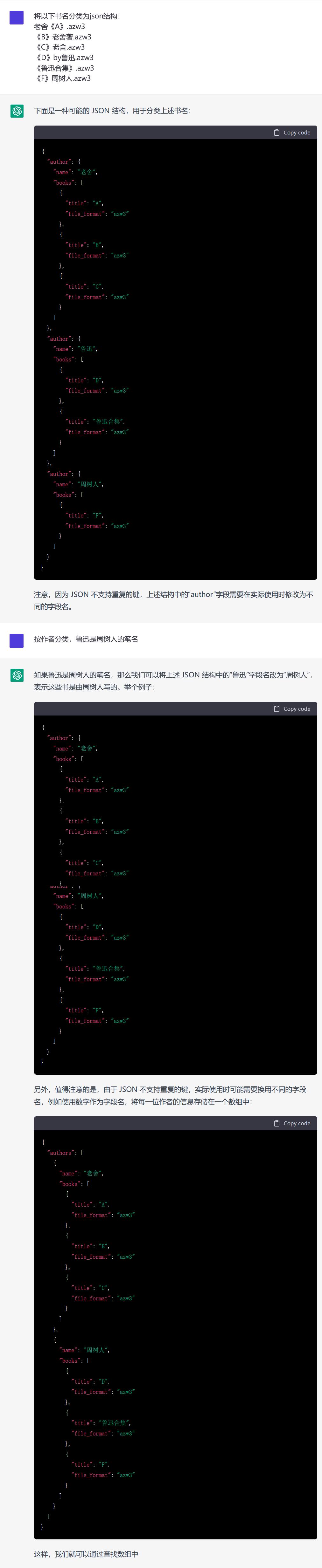
首先感谢 @1113 提供的chatgpt试用接口。
使用部分实际数据,借这个试用接口测试了一下,结果如下:
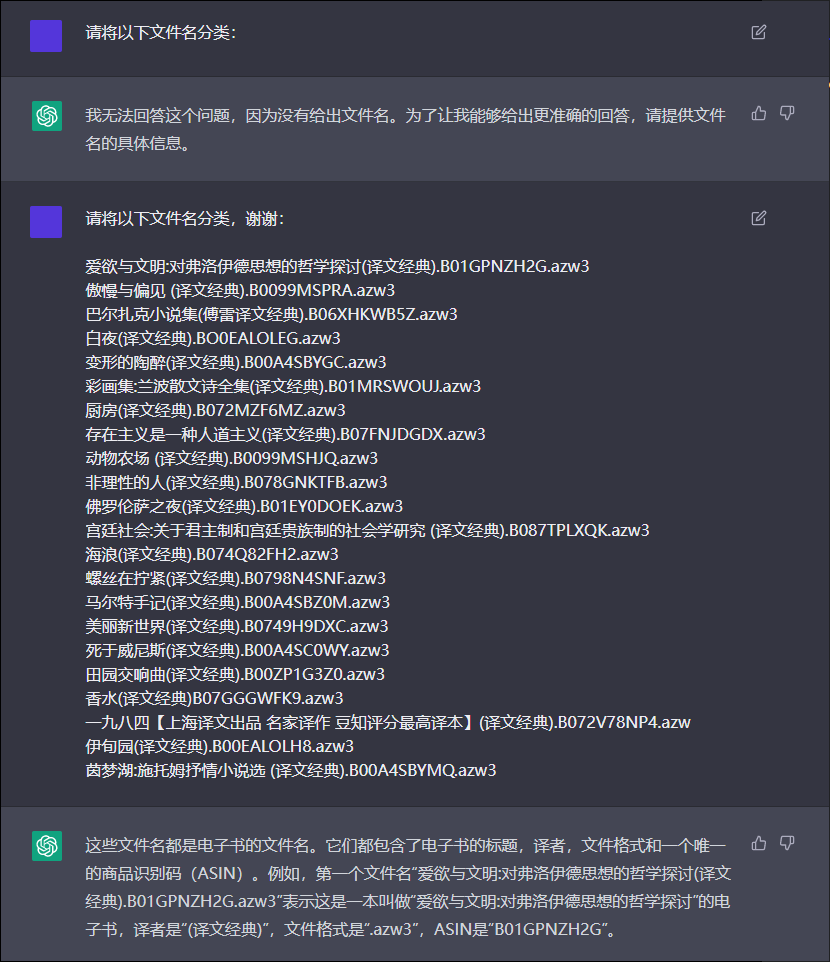
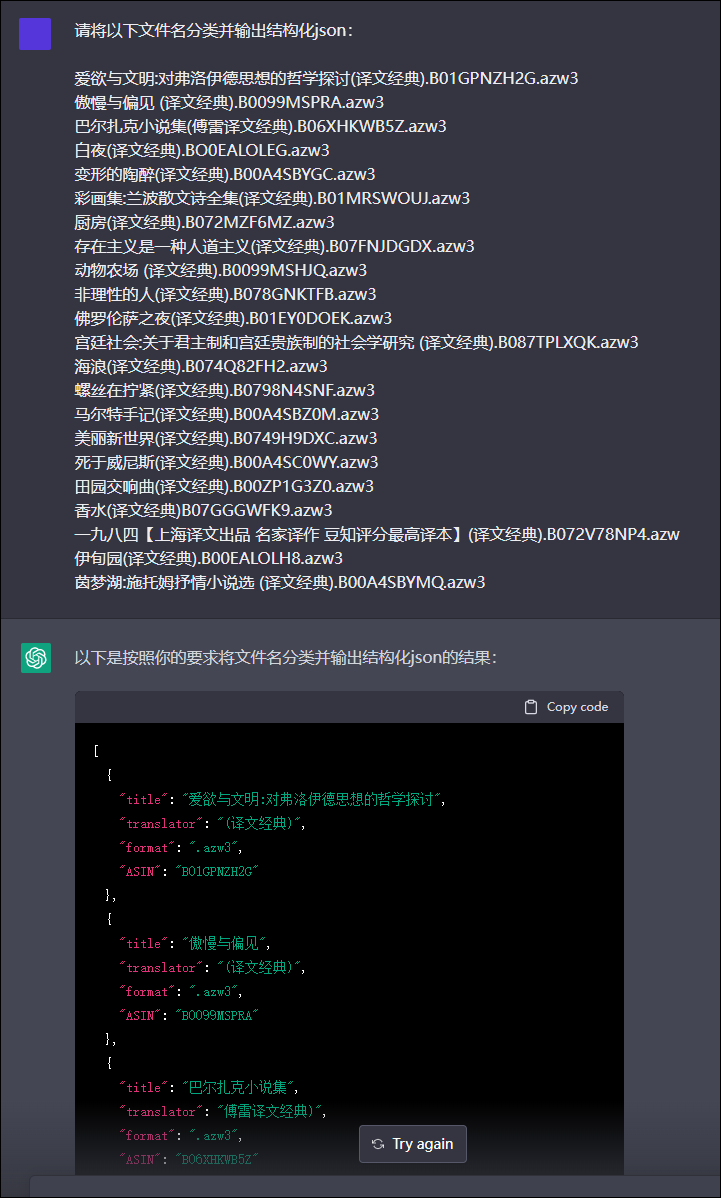
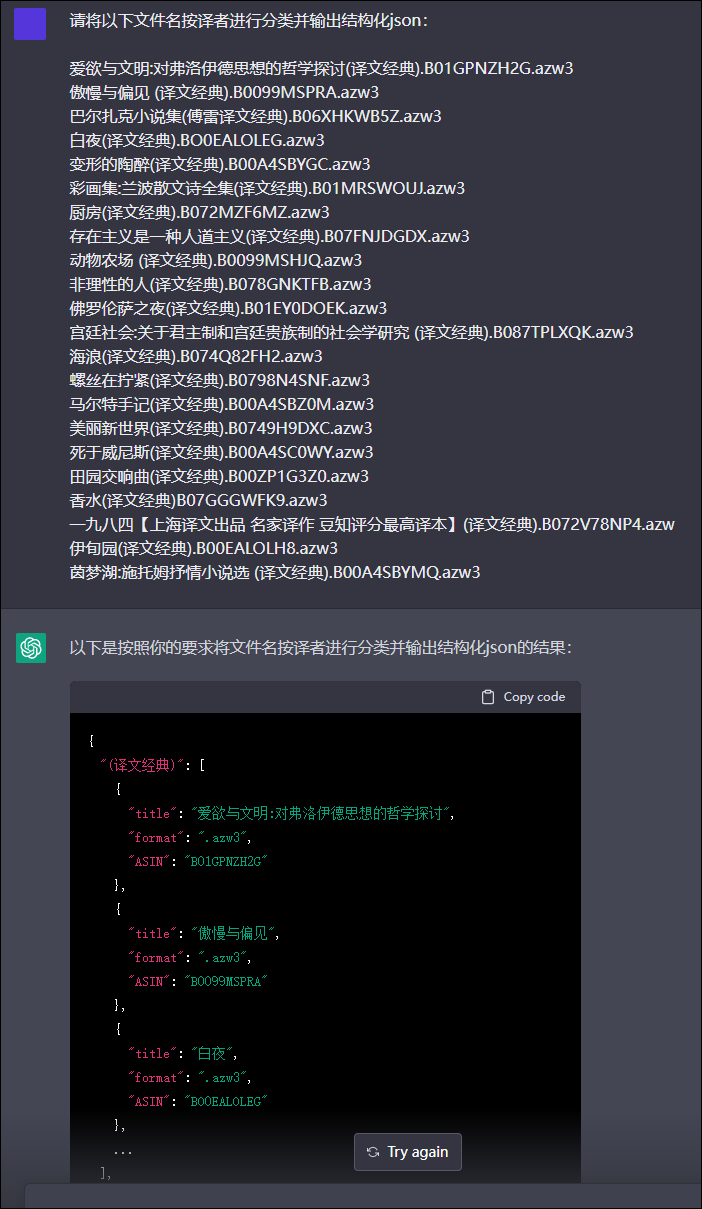
从结果可见,通过不断改变话术,可以诱导AI提供更加符合要求的答案,但可能因为是试用版的原因,AI只能提供缩略版或者说不完整版的答案。
但不管怎么说,至少能看出,AI是有可能圆满解决此类问题的,毕竟天花板很高,现在做不到,也许下一个版本就能做到。