原始链接在: Easy Scraper - 不用编程,可视化爬虫,一键获取网页数据,可能是最简单的网络爬虫了[Chrome] - 小众软件
Easy Scraper 是一款非常简单易用的网络爬虫工具,适用于 Chrome 浏览器,完全可视化操作,只需提交 url 列表,并选取任意一个页面中的所需要的区域,就可以实现批量获取数据、文本了,可导出 .csv、.json 格式。@Appinn

爬虫是什么?
这里的爬虫,指的是网络爬虫,一般需要自己写程序,比如 python 语言就经常用来写爬虫。主要功能是自动收集网页信息,比如你想获取电商所有的手机价格,一页一页翻也不是不行。但会写程序就很快。
Easy Scraper
Easy Scraper 是个 Chrome 扩展,使用超级简单。
针对单个页面
比如小众软件主页(https://www.appinn.com),想要获取最新文章列表,只需要点击扩展栏的 Easy Scraper 按钮,弹出的新页面里,点击 Change List 按钮,然后将鼠标移动到你想要获取的数据上,这里是最新文章,Easy Scraper 就帮你获得了所有相似的内容数据,还包括 URL、图片链接、分类链接、时间、摘要等信息:
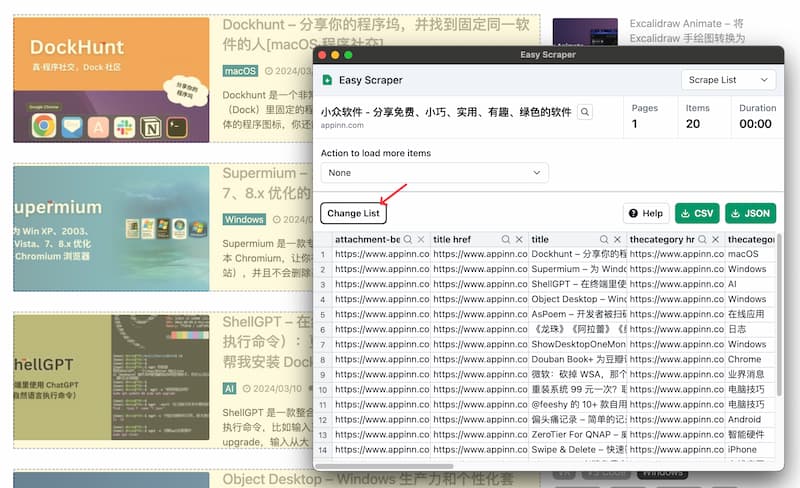
然后导出数据处理,是不是很赞。
针对多个页面
如果你想同时处理很多个网页,那需要先获得这些网站的链接(比如通过上面针对单个页面的方法),然后就能批量处理了。
官方有一个示例视频,非常形象的展示如何获得 amazon 产品的标题、价格、评分:

就…很容易。
特色功能
- 一键爬取:对任何网站的任何列表都能一键爬取。
- 深度抓取:在获取了一系列网页链接后,可以对每个链接都进行进一步的抓取。
- 数据导出:你可以把抓取的数据保存为CSV或JSON格式,方便后续使用。
- 针对动态内容处理:对于使用 JavaScript 渲染的内容也能妥善处理,保证你从复杂的网站上也能抓取到数据。
青小蛙让 AI 举了一些例子:
如果你在进行一些市场研究,比如需要收集某个产品在各大电商平台的价格和评论,使用它就太方便了。
如果你需要写一篇关于某一主题的文章,但又觉得手动搜索和排列资料很麻烦,那么 Easy Scraper来自动汇总相关网页的内容。
获取
原文:https://www.appinn.com/easy-scraper/
下一期,我们来研究如何使用 GPT 处理 .csv .json 文件内容吧。