一个小学题目:
小明和爸爸、妈妈三个人分7个苹果,爸爸妈妈分得的数量必须相等。小明怎么分,可以让自己吃到最多苹果?
智谱清言居然没做对,有点出乎意料。:

我试了通义和DeepSeek,它们都能正确解答。

这道题其实不算难,智谱清言没答上来,让我很意外。
一个小学题目:
小明和爸爸、妈妈三个人分7个苹果,爸爸妈妈分得的数量必须相等。小明怎么分,可以让自己吃到最多苹果?
智谱清言居然没做对,有点出乎意料。:
我试了通义和DeepSeek,它们都能正确解答。
这道题其实不算难,智谱清言没答上来,让我很意外。
这题chatgpt 4o第一次回答也答错:

我再试一次就变成:
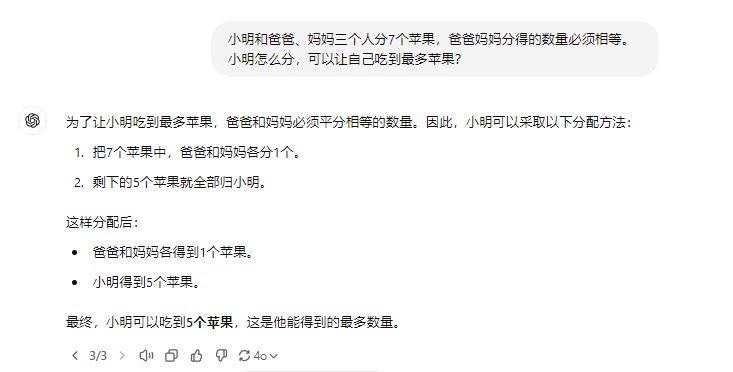
切到4o mini,回答是这样:

Gemini Flash:
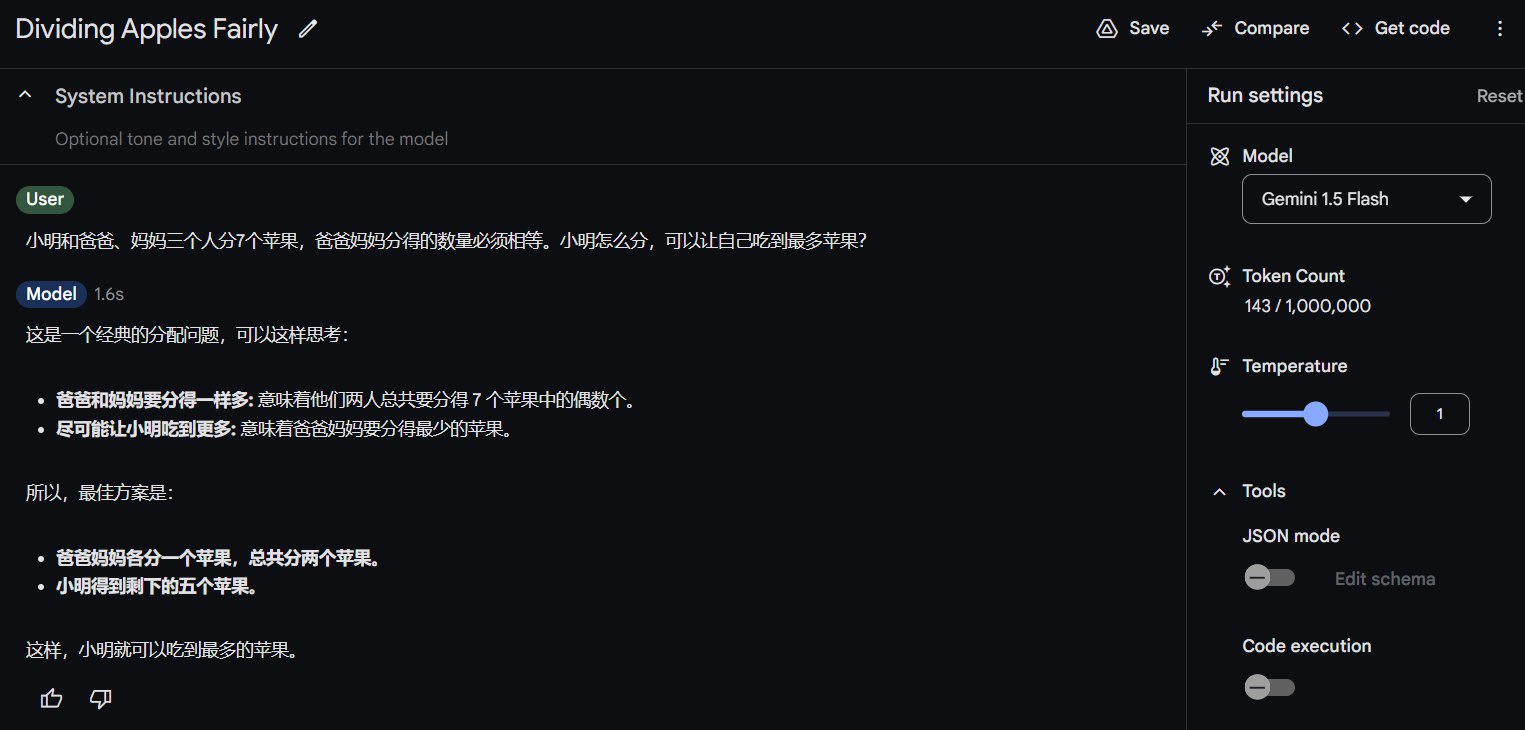
Gemini Pro:
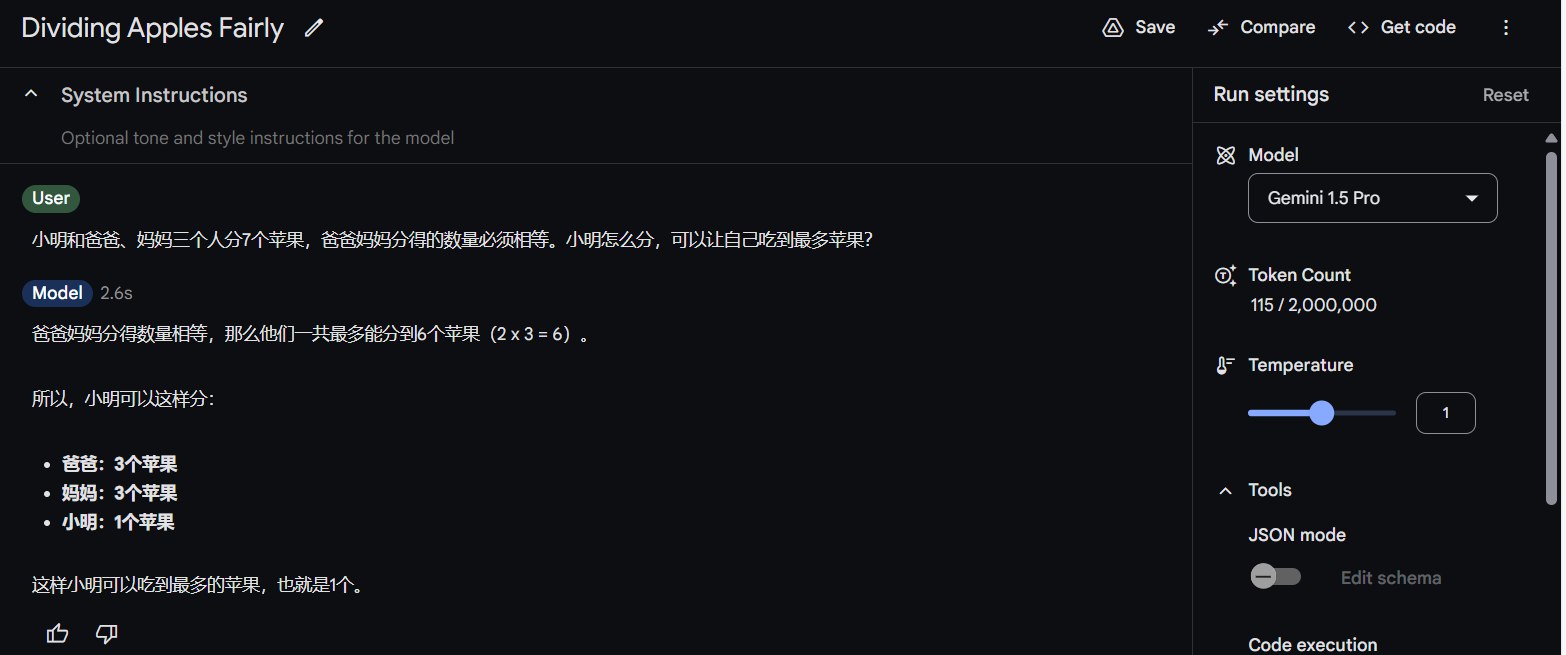
结论就是:这些大模型的回答都不稳定,有时候答对有时候答错,使用大模型还是需要做检查,不是所有答案都完全采信。
在算法上AI模型本来就是在输出一个概率上最可能让你满意的字符排列,
而不是逻辑推理的结果。
没想到这个题 ChatGPT 4o 也不能一次搞定。最近主要用 DeepSeek、通义千问和智谱清言,基本的问答都没啥问题
不要问大模型任何你无法检验结果的问题。
能检验结果的问题最后就变成了我在训练它
智谱最强的glm-4-plus试一下。
首次答案,是爸妈0,小明7个。
然后补充一个条件,每个人不能为0和复数,就得到1+1+5了。
然后flash和air版模型都翻车,从给出的推理步骤来看,这两个轻量级模型思路大概是脑子不够。
网页版模型为了省钱估计给的都是轻量模型吧。
其实从回答结果来看,与其说是逻辑推理能力有点弱,不如说是对题干的逻辑抽象能力有点弱。
试了一下 glm-4-plus 确实强,是旗舰产品,价格会让钱包抗议,你用的是 API 吗?
用的 api,之前注册送一个月资源包。
安心啦,绝大多数人都还没有训练他的能力。
目前这些模型的核心都是统计并输出最可能出现的字符,说白了是一种“语言模型”。从本质上并不具备数理逻辑能力。不要用大模型来做精密计算。
我觉得LLM+程序代码应该是最有前景的方向,用LLM把题目翻译成程序代码,也就是把自然语言翻译成机器语言,然后数学部分就全部交给程序了。
这其实就是做应用题、搞科研的流程:列方程是语文题,解方程是数学题。
这样很大程度上能解决LLM不可靠的问题,因为程序运行还是比较可靠的。
现在看,Claude已经很接近这个完美的流程了。
智谱在做技术上的东西还是有差距的,无论是免费模型还是付费模型。
这题问的真蠢,既然是分配,以人性化的角度来看分配0个正常吗。1+1+5就是很合理的答案
