2980条记录了,如何一键导出来呢?因为很多都折叠起来,需要展开
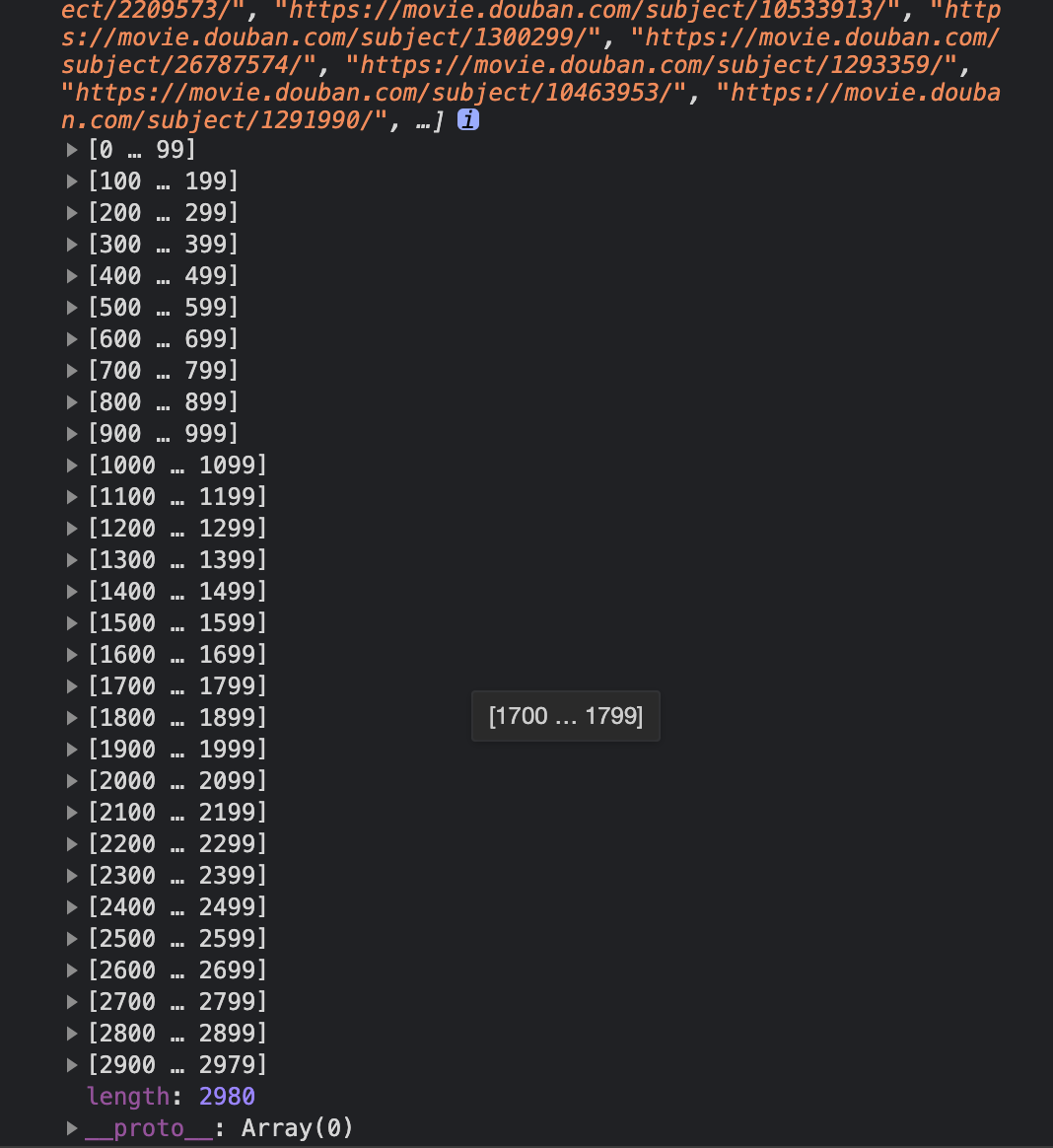
我倒是感觉你这个需求更适合青蛙的做法 豆瓣上不感兴趣的也标为“已看过”
如果你希望把不感兴趣的和真正已看过的区分 不如在本地维护一个已看过的列表
urls.join(‘\n’)
我手机打的,换成英文单引号,urls.join(‘\n’)
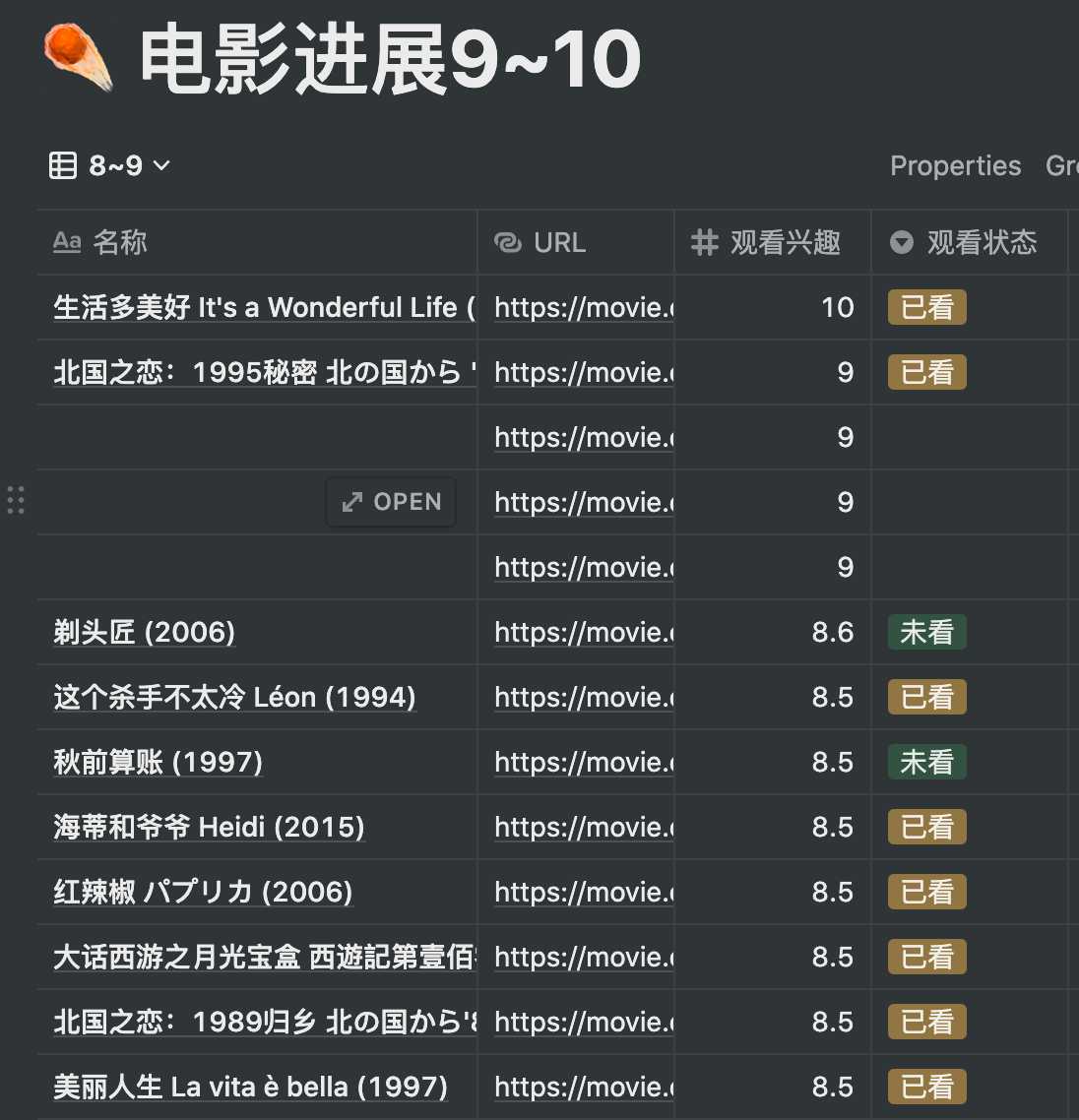
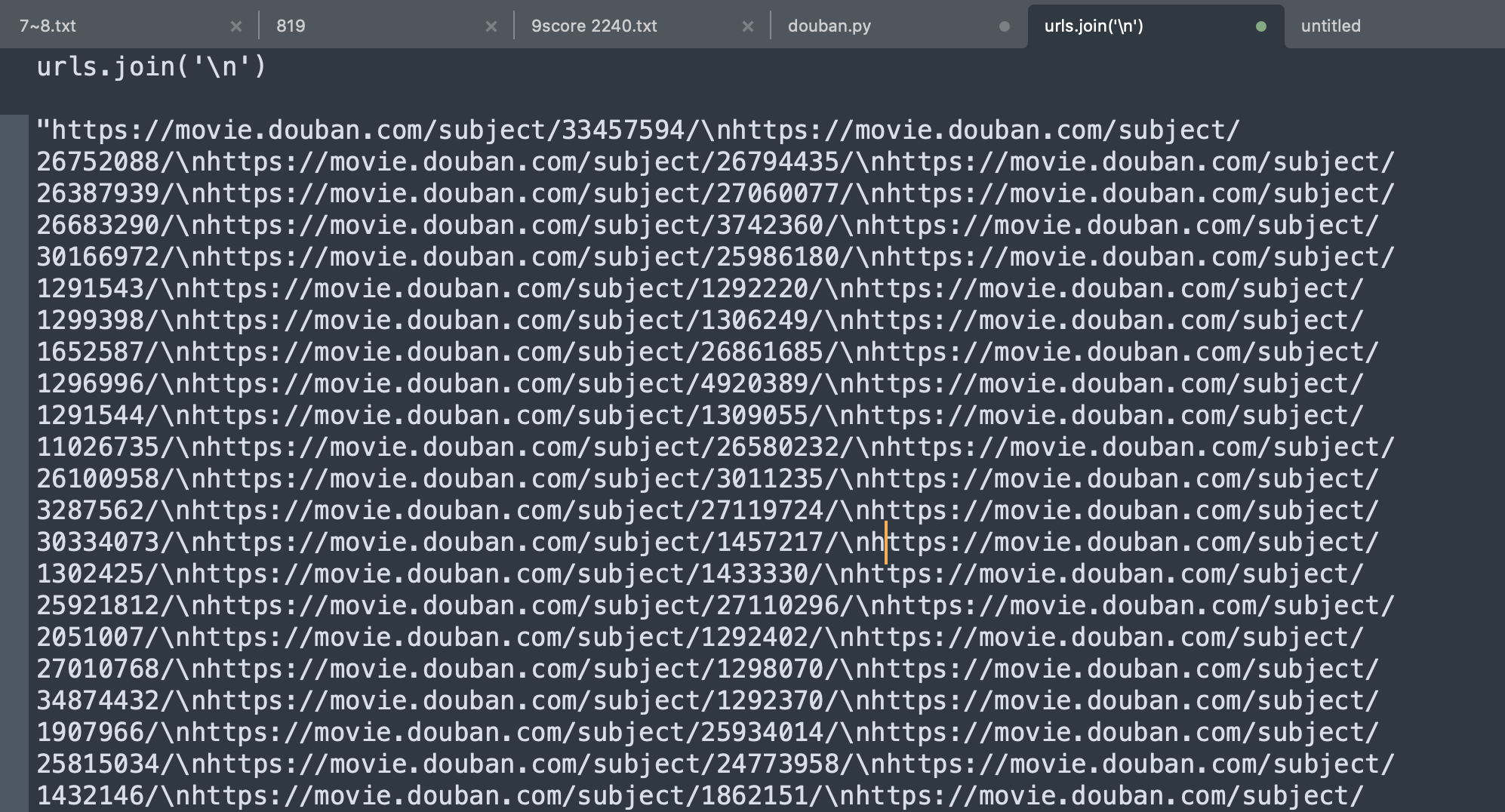
输入这个命令后 urls.join(‘\n’)
好像停止抓取了,这个命令会停止抓取的么?
先完成抓取,然后用这个很短的命令拼接,不过么……我这两天也发现这样拼接并不能正确转义,好奇发生了什么,印象中以前是可以的。
不过你把 \n 换成一些特殊字符,把拼接后的内容复制到文本编辑器里来一次查找替换也行
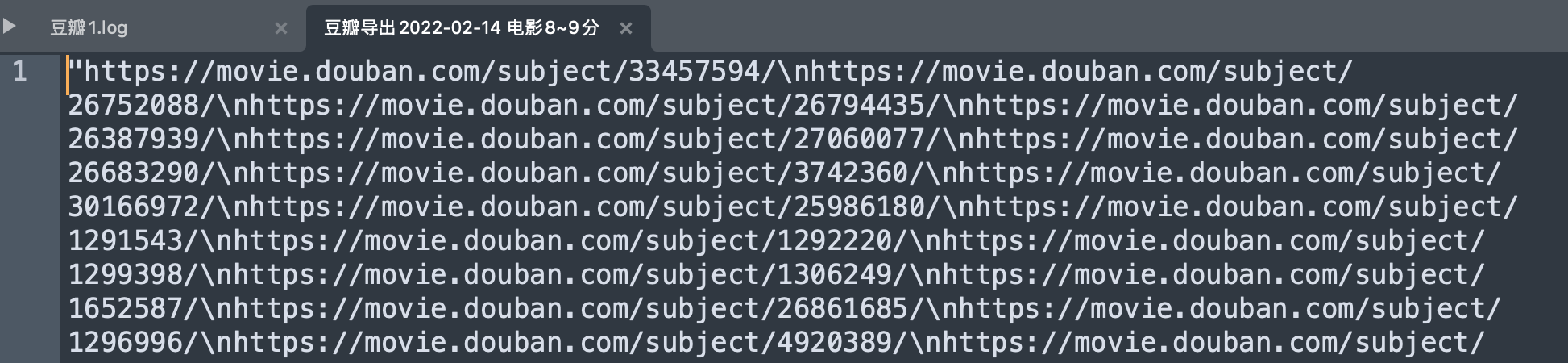
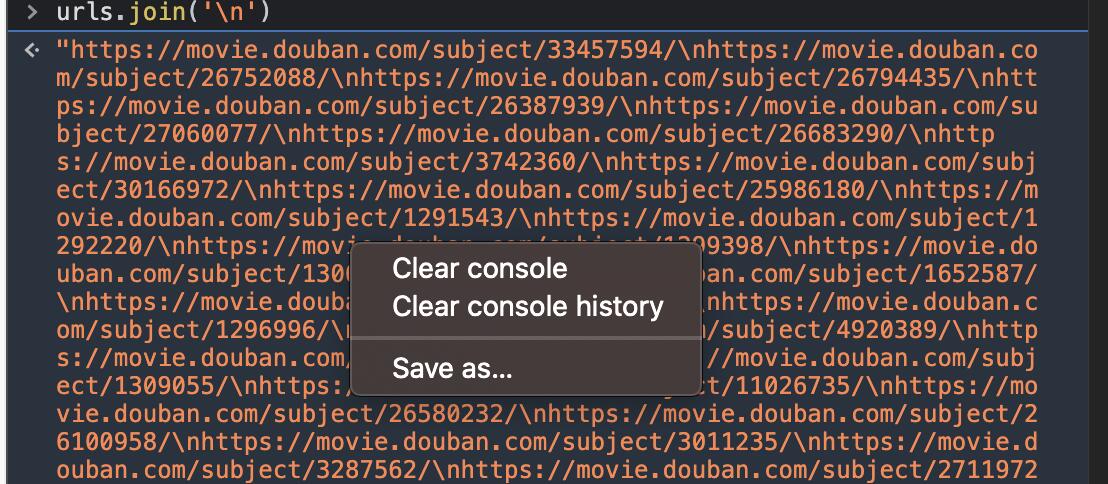
我刚测试了,不用麻烦,其实这个看起来很乱的结果只是显示问题,复制到编辑器里 \n 就是换行了
输出后不要直接copy啊,得右键“复制字符串内容”
你是复制到哪个编辑器里的?我复制到Notion与sublime没有断行。
我用了两次替换,8~9分的电影记录导出来了,共3120条,不知道有没有加载全
明天再导出一次试试
链接: https://pan.baidu.com/s/1xJo3uV1w4BEZLo5_XibHsQ 密码: g3iu
–来自百度网盘超级会员V6的分享
import json
import time
import urllib.request
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=8,9&tags=%E7%94%B5%E5%BD%B1&start='
herders = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML,like GeCKO) Chrome/45.0.2454.85 Safari/537.36 115Broswer/6.0.3',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'
}
num = 0
data = []
while True:
req = urllib.request.Request('{}{}'.format(url, num), headers=herders)
response = urllib.request.urlopen(req)
html = json.loads(response.read().decode('utf8'))['data']
if len(html) > 0:
data = data + ['{},{}\n'.format(x['title'],x['url']) for x in html]
else:
break
num = num + 20
time.sleep(50)
with open('douban_movie.csv', 'w') as f:
for line in data:
f.write(line)
我看了一下你的表格 是需要title和url吧 这个代码能直接保存为csv
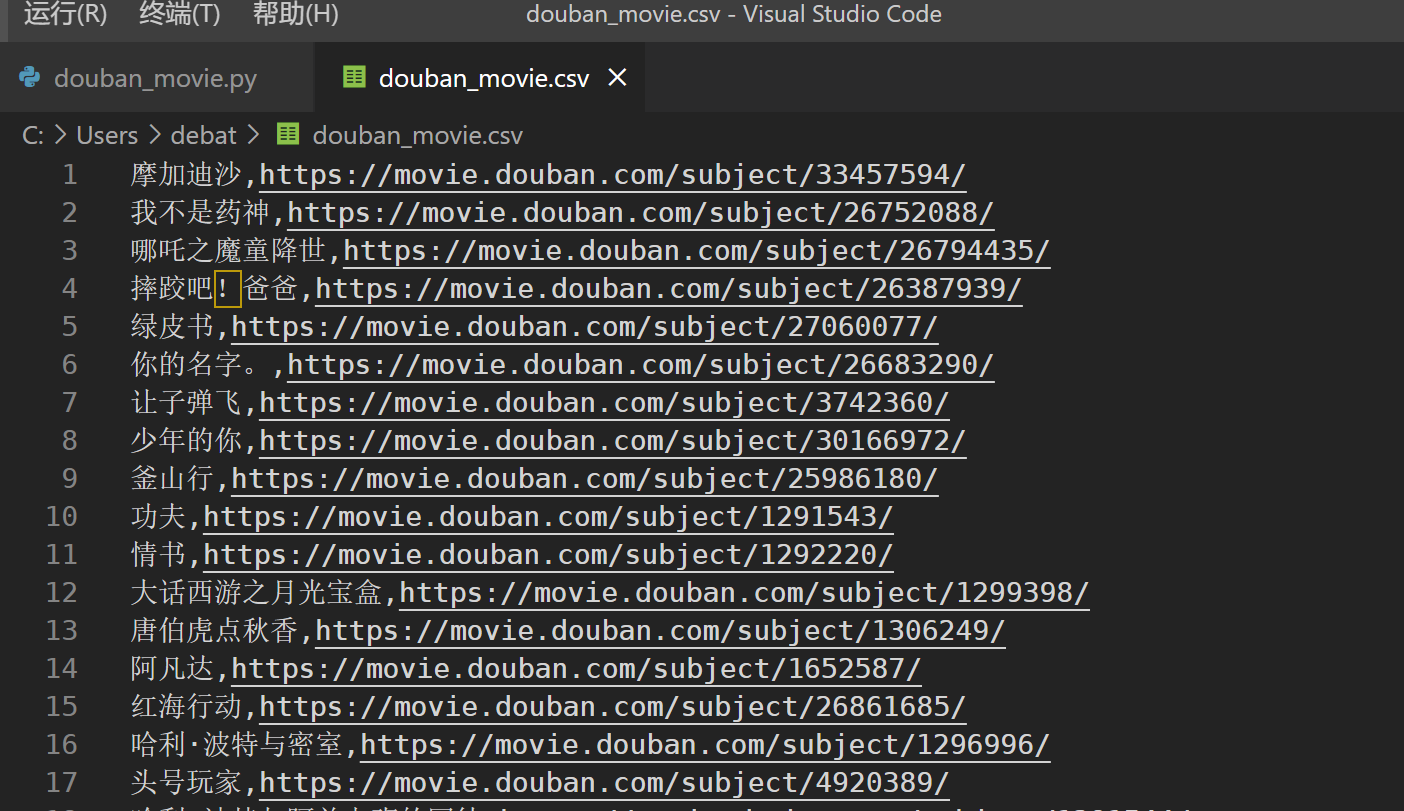
不过是python3的代码 刚才试图改python2想起来有中文编码问题所以放弃了(这个可能也有点问题…… 不过在sublime里改一下应该就好了)
所以,mac自带的python不行,我要卸载,安装python3才可以吧?
对 如果你对python2没有其他需求的话 卸载重装就行
不过既然你之前装过2说不定就有需求……所以说脚本可能还是js之类的更方便……
哭!!
让我试试卸载python2,再装python3,希望我能成功!
加油!我能成功!
不用卸载,2和3可以共存
啊对 改环境变量就行 python3可以就叫python3的 甚至不干扰之前装的东西……