现在有一些网页是响应式的,比如本小众软件论坛,这种网页无论是使用另存为还是打印PDF,或者使用一些诸如SingleFile等扩展,都无法将网页内容完整的保存下来,只会保存当前显示出来的内容。
所以想求一款可以将此类网页保存下来的工具。
可以将网页保存为html、mht、mhtml、pdf等,主要是要可以复制网页内容。
你可能需要整站下载工具,把相关的依赖文件全部下载到本地,idm的站点下载功能可能有点用
試試保存為PWA,如果網站實現的話,是可以實現一定的離線操作的。
+1
我也想请教大家同样的问题!困扰了我很久了!有个叫简~媒的(问题已解决url就删掉了)
这个网站所有的文章都是这样的,chrome浏览器里直接按F12,看不到任何正文内容。(已更正 其实是我没找对地方,F12能看到正文,谢谢Huhu指点)
用curl命令去下载,下载不了正文。
**比如我想用
**curl -O https://XXX.html
下载,结果本地得到的一个html文件是个空壳,正文部分是没有的
什么idm之类下载工具都不行。
但是浏览器里save as成html就有正文内容了。
我不懂网页制作,但是我猜测这种就是题主说的【响应式网页】吧。
目前我想从这个网站批量下载很多篇文章,网址都整理到一个excel里了,但使用curl不行,一个一个按save as几百页太傻了 求高手支招!

SingleFile 可以在选项里面取消勾选【移除用于备选设备屏幕的样式表】,然后保存网页时就能达到满意的效果
这应该是lazyload的问题。
针对本论坛,或者采用类似论坛程序的论坛,可以禁用js之后刷新再保存
这跟楼主的问题应该有区别。这个网页正文内容大概是js生成的,所以用curl下载不行,因为没有运行js。
https://www.bilibili.com/video/av92655544/
可能得用 selenium ?
谢谢!我似乎明白了我的问题和楼主的问题是不一样的,我的问题应该是类似这种的:
如何使用curl获取JavaScript加载的动态网页?
selenium需要花点时间研究,我打算先搜搜PhantomJS试试。 ![]()
更新:selenium太复杂了暂时没研究,PhantomJS对付这种网页也不行呦,不过还是学了一招
数量少,我就用 QQ 截图的 文本识别 :)
curl默认是get,但是这个网站获取文章是post,你需要模拟一下post,带上两个参数,返回结果是个json
var param = {materialId: id,mcType:mcType,isCreate:isCreate};
$.post(“/s/article/materialPreviewDetail”, param, function (result) {
//log(‘materialPreviewDetail:’+JSON.stringify(result));
if (result.code == 200) {
//渲染模板
var material = result.data;
articleTitle.html(material.title);
// 网易号把第一个字变大
material.content = oneBig(material.content)
articleContent.html(material.content);
getUserInfo(); // 获取用户相关信息
}
});
};
谢谢! 我尝试用
curl -d "corpusId=UUID&source=" -H "referer:[https://www.l3gt9.com/f/content/corpus/UUID.html](https://www.l3gt9.com/f/content/corpus/UUID.html)" -H "origin: https://www.l3gt9.com" https://www.l3gt9.com/f/content/corpusPreviewDetail -o 1.txt


结果就是你说的json:
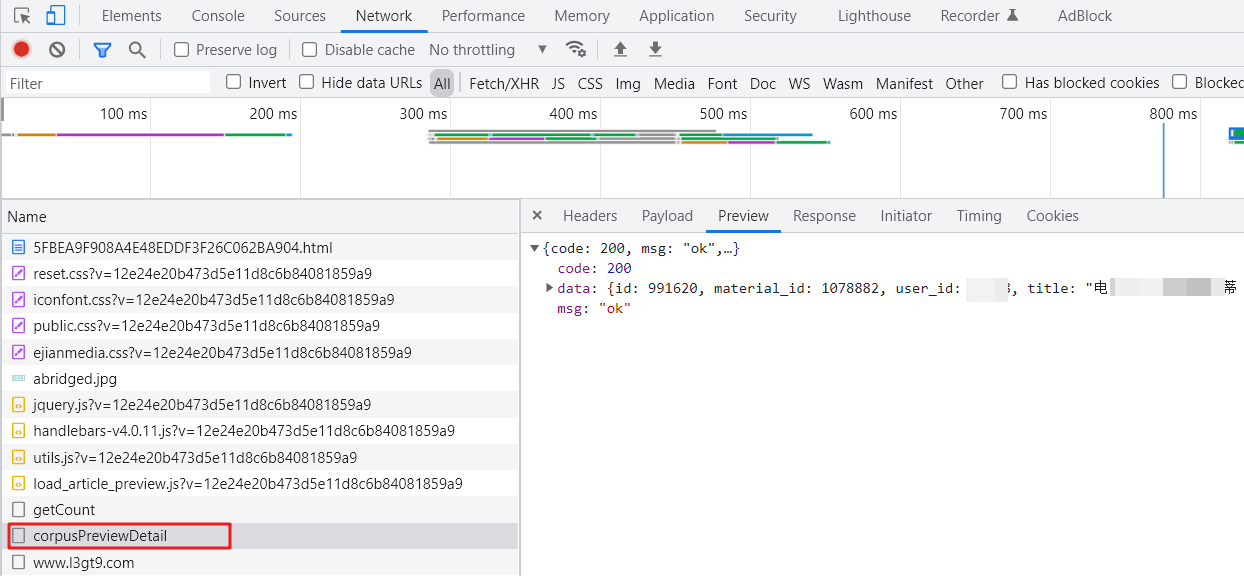
问题完美解决了!
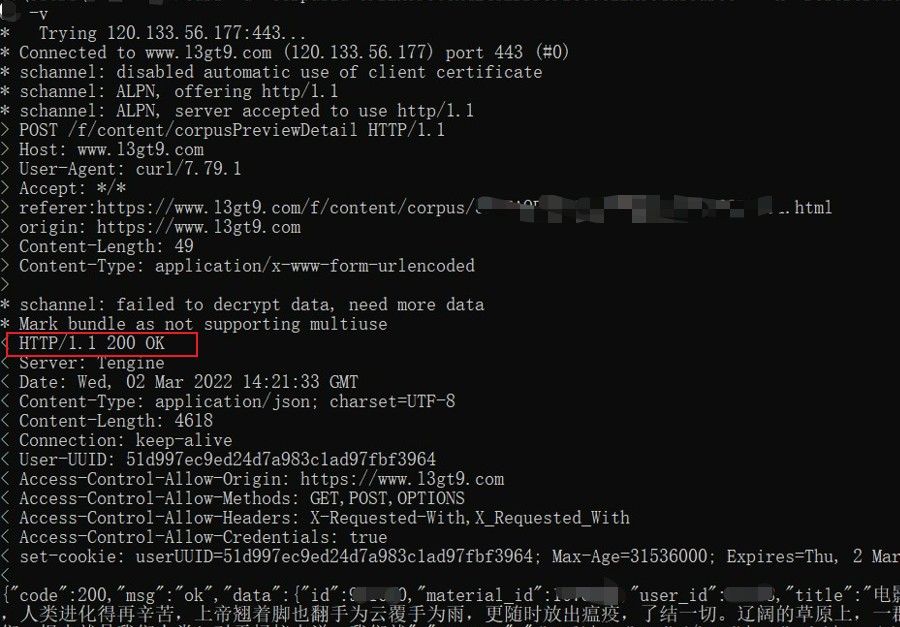
解决关键:这个网站必须用 post, post必须带2个参数corpusId和source,而且必须用-H带上origin: 和referer:
太感谢了!
刚发现楼主不是我,没办法把你的回复设为“解决了问题”
curl -X POST -d “corpusId=5FBEA9F908A4E48EDDF3F26C062BA904&source=” https://www.l3gt9.com/f/content/corpusPreviewDDetail
是post带两个参数corpusid和source,不是curl带两个参数