论包管理器的重要性
7分以上也有不少好看的
不过楼主心真大,不先审一下代码就运行的话,万一给你个rm -rf。。。
曾经学习网上的优化技巧……Win+X 然后 U U ……大概这样吧,那一瞬间我是真的傻眼的
1 个赞
rm -rf这种明眼人都能看出来 而且系统也不一定执行
试试:() { :|:& };:
直接curl https xxxx >> result.txt 吧。如果不是经常要去爬,只是收集数据,没必要用代码。
这是递归加上倍增申明函数耗内存的shell吧,所以最烂的代码就是无脑申明一大堆函数又不用的那种,就像为了找东西方便就在桌上堆满杂物
赞![]()
我基本都是这样 ![]()
我现在用 Trakt 了
Trakt 更多是用来记录电视剧看到哪一集了吧?我是因为还会记录读书和音乐,所以都还在豆瓣上
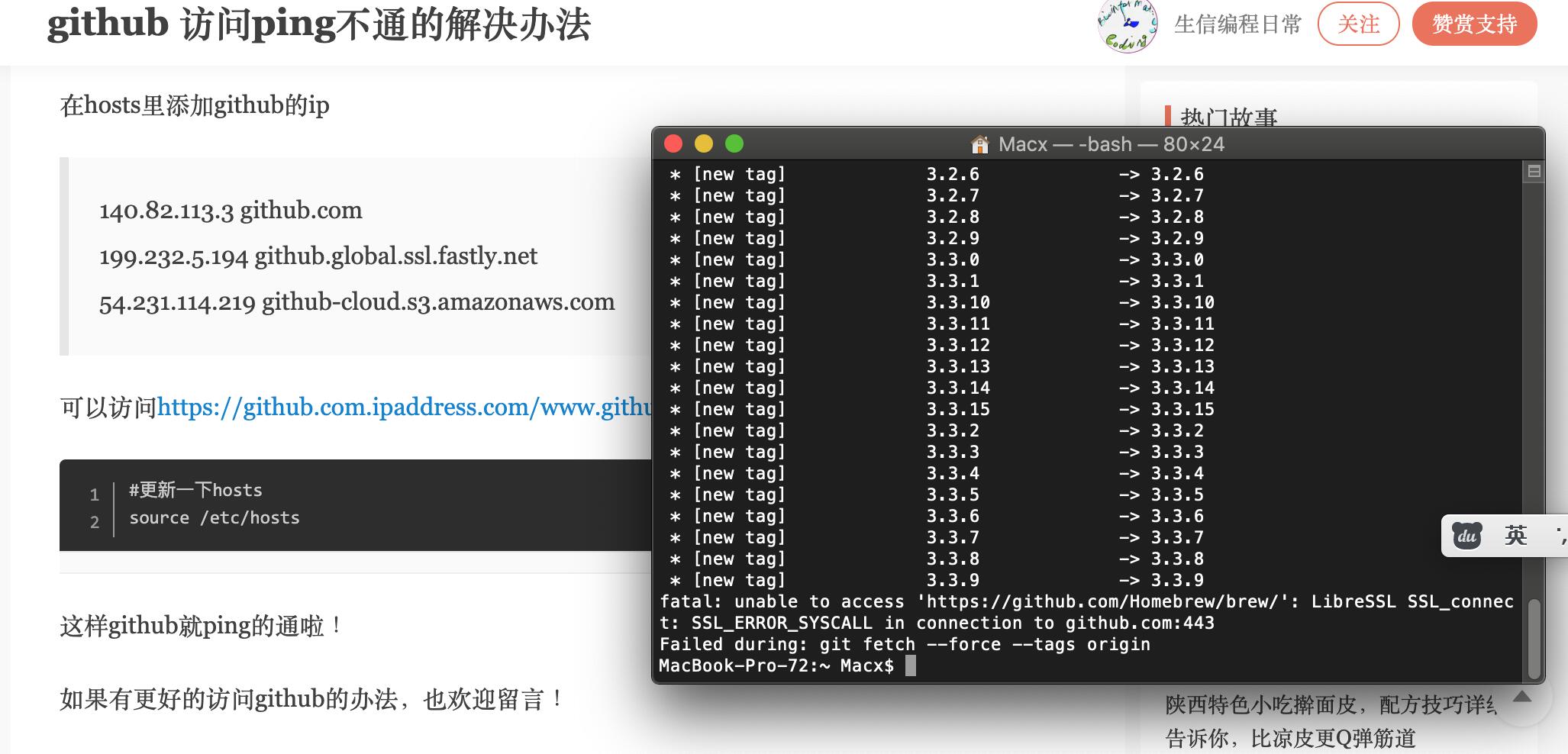
仿佛不知不觉间还是被大家引入了编程的无底深渊 ![]()
不愿意跟长城折腾而且对homebrew没有执念的话 可以直接去官网下载安装包……
我安装了python3,也修改了环境变量使python默认,但是运行仍然出错:
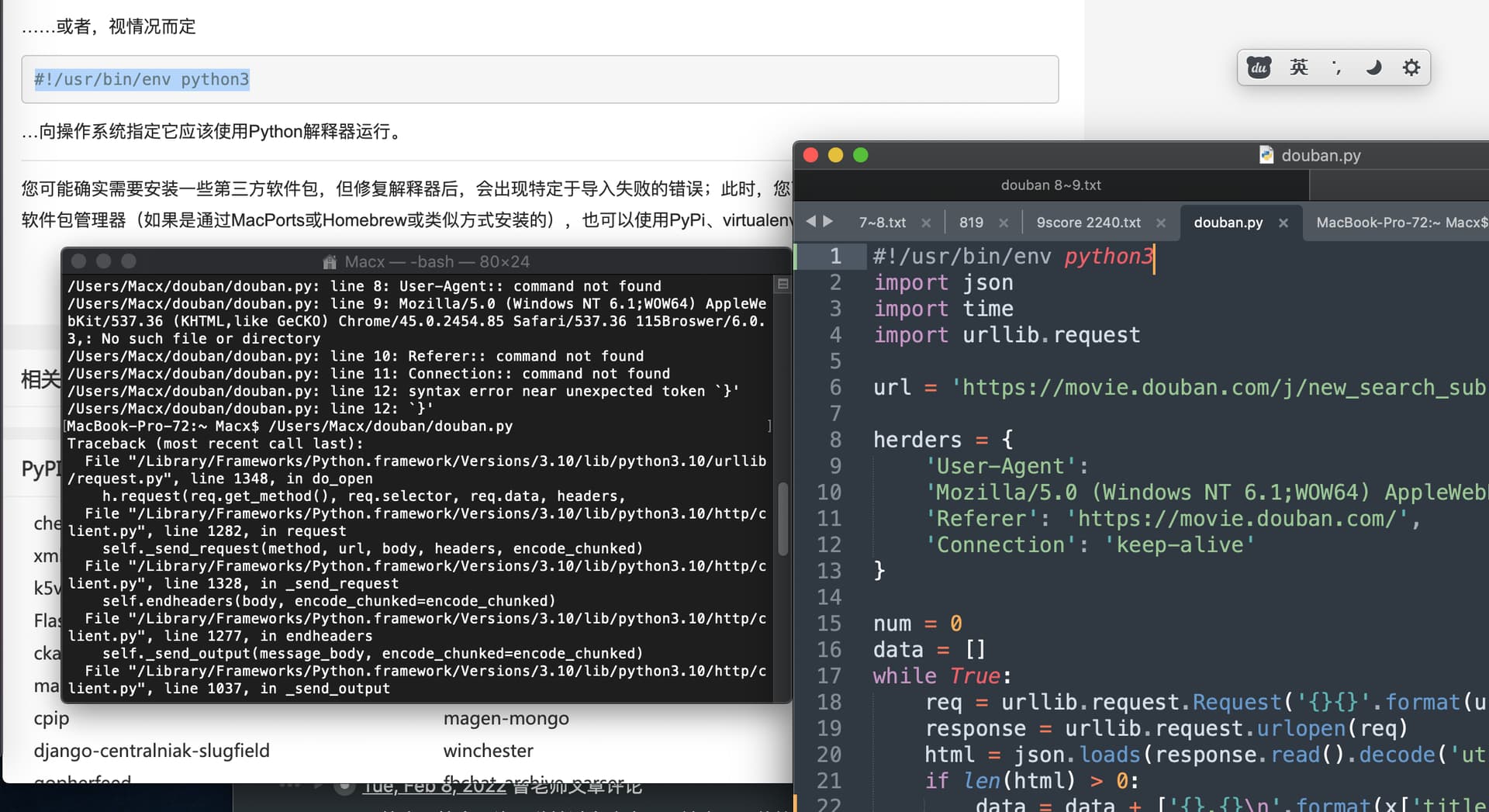
然后,昨天东方永页机作者提供的代码,今天好像一直卡在2680条,我手工点击时导出有3180条
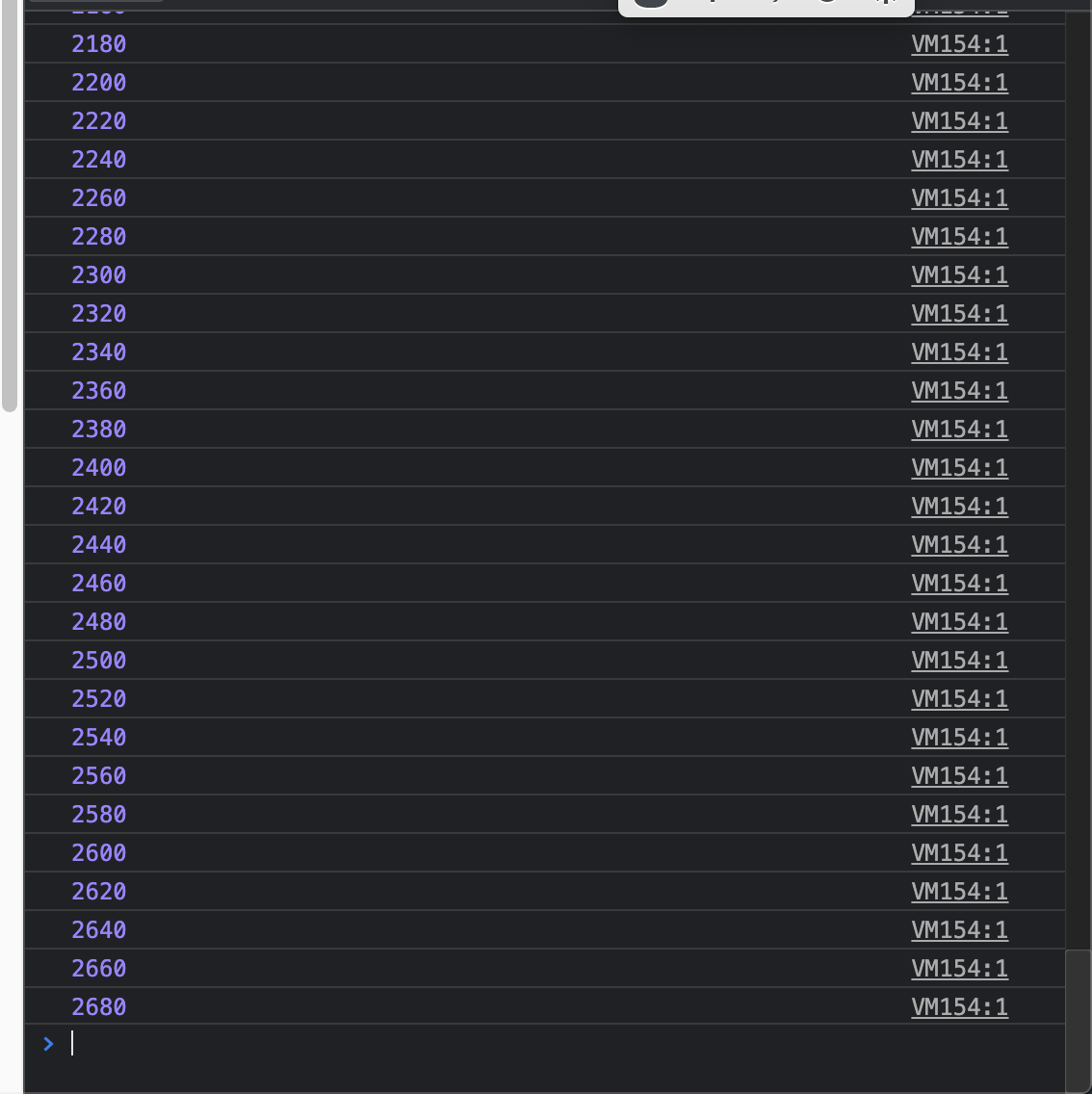
看上去好像需要homebrew才能安装完整的库(依赖组件?)吗?
明天继续弄弄
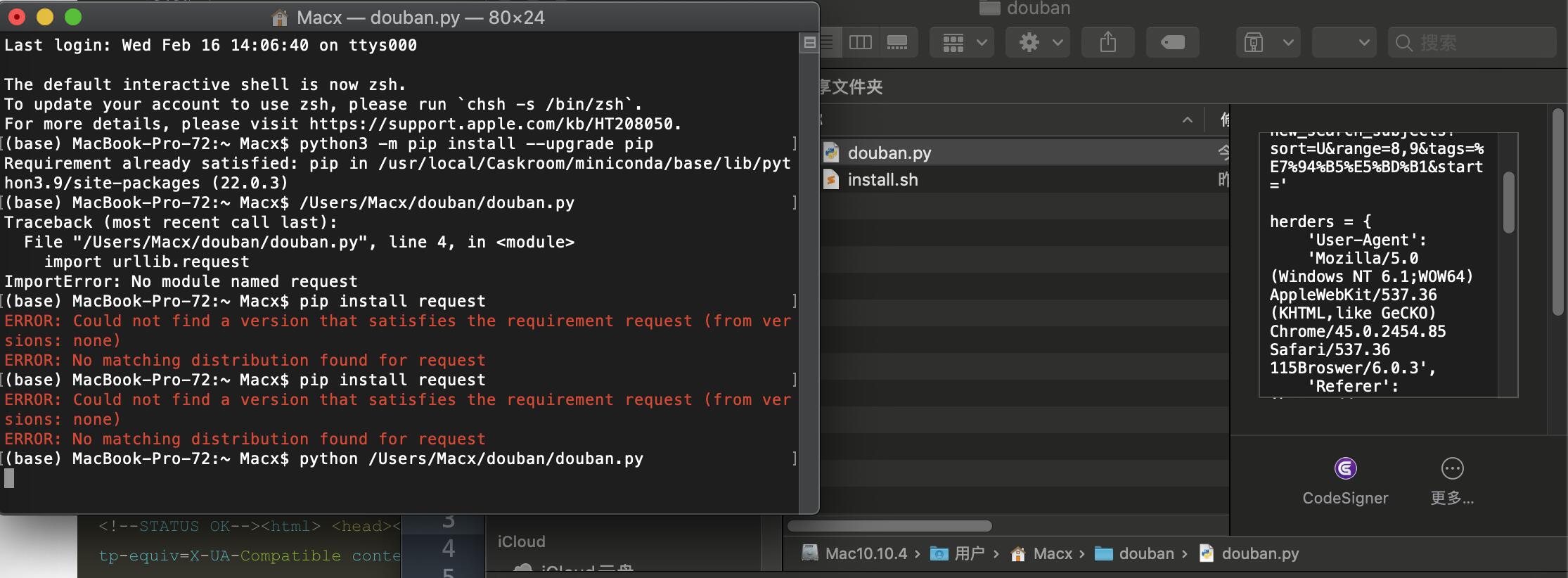
PS:好像那个request没有装成功么?
代码
import json
import time
import urllib.request
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=8,9&tags=%E7%94%B5%E5%BD%B1&start='
herders = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML,like GeCKO) Chrome/45.0.2454.85 Safari/537.36 115Broswer/6.0.3',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'
}
num = 0
data = []
while True:
req = urllib.request.Request('{}{}'.format(url, num), headers=herders)
response = urllib.request.urlopen(req)
try:
html = json.loads(response.read().decode('utf8'))['data']
except Exception as e:
print(repr(e))
time.sleep(600)
continue
if len(html) > 0:
with open('douban_movie.csv', 'a') as f:
for idx, x in enumerate(html):
line = '{},{},{}\n'.format(idx + num, x['title'], x['url'])
f.write(line)
print(line[:-1])
else:
break
num = num + 20
time.sleep(30)
我又改了一点 让抓取结果能随时保存并且输出查看 要是运行中断了的话把num改成已有的行数就好
最后一行是两次抓取的间隔 我这边5秒一次没有触发豆瓣的反爬机制
你直接运行一下python3 /Users/Macx/douban/douban.py看看 如果报错的话把全部报错信息发出来看一下
urllib是内置库 不需要额外安装 我专门没用Requests这个人类的库……
当前star 8~9的数量应该在6868…
文件链接 – 有效期 2022-03-16
# 有数据 6850+18 = 6868
https://movie.douban.com/j/new_search_subjects?sort=S&range=8,9&tags=%E7%94%B5%E5%BD%B1&start=6850
# 无数据
https://movie.douban.com/j/new_search_subjects?sort=S&range=8,9&tags=%E7%94%B5%E5%BD%B1&start=6870
访问太快会触发反爬机制
摘要
import json
import time
import requests # pip install requests
import pathlib
import random
import logging
import os
from datetime import datetime
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
json_dumps = lambda x: json.dumps(x, ensure_ascii=False)
DATA_PATH = '/data/douban/'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML,like GeCKO) Chrome/45.0.2454.85 Safari/537.36 115Broswer/6.0.3',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'
}
def main(_range = '8,9'):
"""
储存路径:
- /data/douban/movie/8_9/0
- /data/douban/movie/8_9/20
"""
page = 0
# _range = '8,9'
while True:
url = f'https://movie.douban.com/j/new_search_subjects?sort=S&range={_range}&tags=电影&start={page}'
file = os.path.join(DATA_PATH, 'movie', _range.replace(',', '_'), f'{page}')
pathlib.Path(file).parent.mkdir(parents=True, exist_ok=True)
# 如果存在文件
if os.path.exists(file):
page = page + 20
continue
try:
r = requests.get(url, headers=headers)
data = r.json()
data['page'] = page
data['_range'] = _range
data['update_time'] = datetime.now().strftime('%Y-%m-%dT%H:%M:%S')
if data['data']:
data_dump = json_dumps(data) + '\n'
with open(file, 'w') as fo:
fo.write(data_dump)
logging.info(f'[{page}] {file}')
else:
print(f'STOP {page} {data}')
break
except Exception as e:
logging.error(e)
time.sleep(600)
continue
page = page + 20
# 每次间隔 6~10s
time.sleep(random.choice(range(6, 10)))
if __name__ == '__main__':
main('9,10')
# 合并文件
# cat /data/douban/movie/9_10/* > /data/douban/movie/douban_9_10.json
我参考这篇教程,使用国内源安装了homebrew。
mac下多个版本的python如何删除? - 知乎
https://www.zhihu.com/question/57839923/answer/2245593029
脚本执行后如下图,没有返回任何结果,是在运行么?要运行结束后才生成csv文件吗?
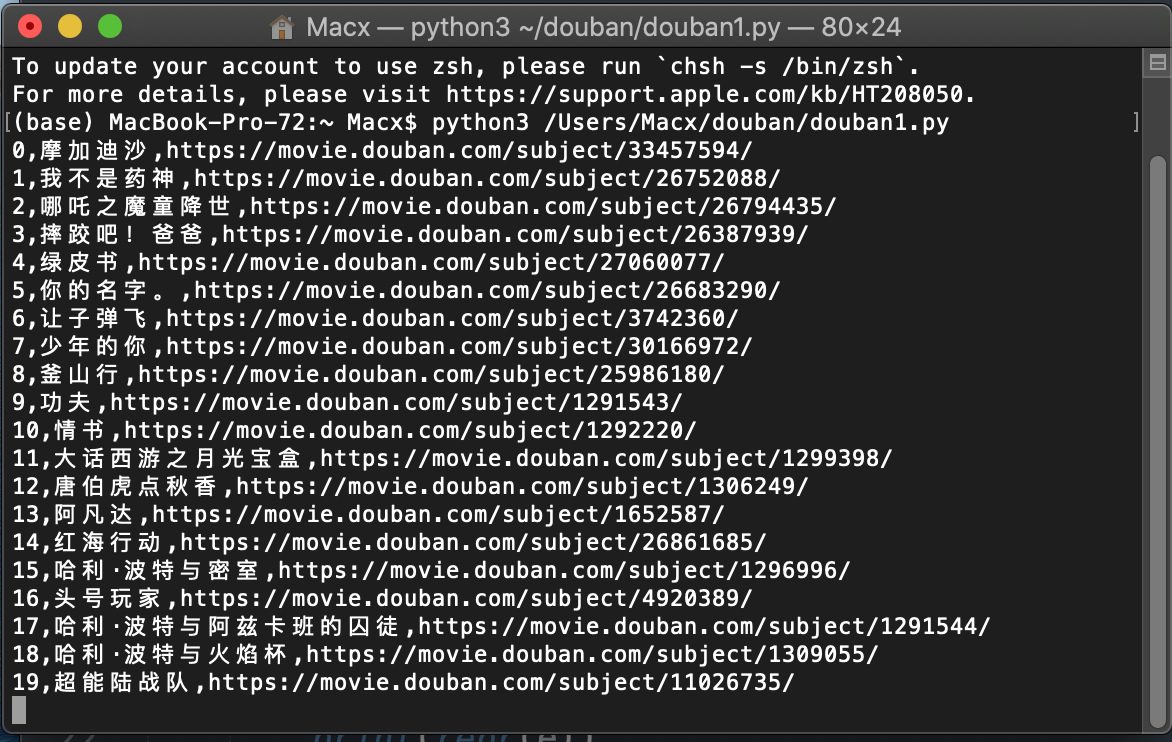
新的脚本是一边跑一边存的 这样应该就没啥问题了
我这边是发现2000条之后就会偶尔获取不到 现在脚本里是获取不到就等20分钟
line = '{},{},{}\n'.format(idx + num, x['title'], x['url'])
保存的内容是这行确定的 如果你还需要什么字段可以自己加
最后恭喜你已经掉进编程的坑里了 祝头发茂密 ![]()