前提:已知ii,u和x都是未知内容。
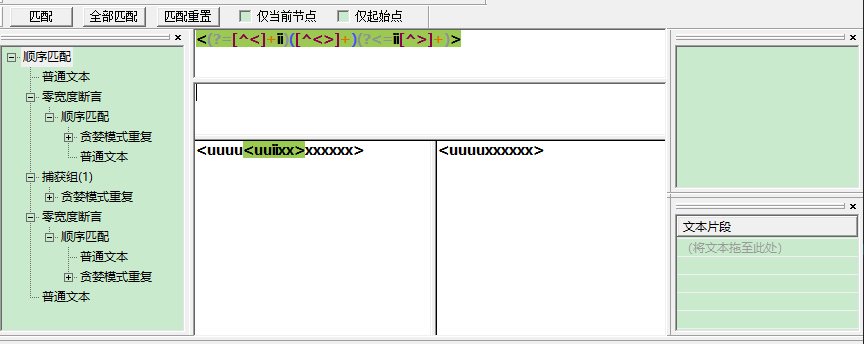
请教如何从字符串 <uuuu<uuiixx>xxxxxx>如何摘除中间(也就是距离ii最近,套嵌最深的)<uuiixx>的字符串得到<uuuuxxxxxx>
谢谢各位大佬啦,因为python的re正则都是贪婪模式,非贪婪的?只能找到后面最近的,不太会整 ![]()
前提:已知ii,u和x都是未知内容。
请教如何从字符串 <uuuu<uuiixx>xxxxxx>如何摘除中间(也就是距离ii最近,套嵌最深的)<uuiixx>的字符串得到<uuuuxxxxxx>
谢谢各位大佬啦,因为python的re正则都是贪婪模式,非贪婪的?只能找到后面最近的,不太会整 ![]()
(<[^<]+)<[^>]+>(.*)
谢谢大佬,不过这个好像不太ok?, 这里面似乎没有体现出ii的寻找匹配呀?
谢谢呀,这种我试过,但是你看在python里面
` import re
a = “<uuuxuxxxxx>”
re.sub(r"<.+?ii.+?>", “”, a) `
结果是这样的:
'uxxxxx>' 它对左边似乎还是贪婪的。
我上面那个是匹配巢式的,
(.*)<[^<]+ii[^>]+>(.*)
匹配ii用这个,注意这两个都是靠分组来提取的
请教一下,什么是“巢式括号”啊?搜了一下,第一个结果就是这个帖子 ![]()
可能是长得跟巢上面那三个笔画一样哈哈哈哈哈哈~
可以试试:
其中 .*? 表示非贪婪匹配所有的字符。
import re
for astr in (
'<uuuu<uuiixx>xxxxxx>',
'<abc>',
'<uuuu<uuixx>xxxxxx>'
):
asub = re.sub(r'(<.*?)(<.*?ii.*?>)(.*>)', r'\1\3', astr)
print(astr, asub)
output:
<uuuu<uuiixx>xxxxxx> <uuuuxxxxxx>
<abc> <abc>
<uuuu<uuixx>xxxxxx> <uuuu<uuixx>xxxxxx>
就是括号外面套括号哈 ![]()
nested 翻译成嵌套比较好 ![]()
我还以为巢式是 巢字头上的 巛,还想着挺形象,哈哈哈哈