montaus
(montaus)
1
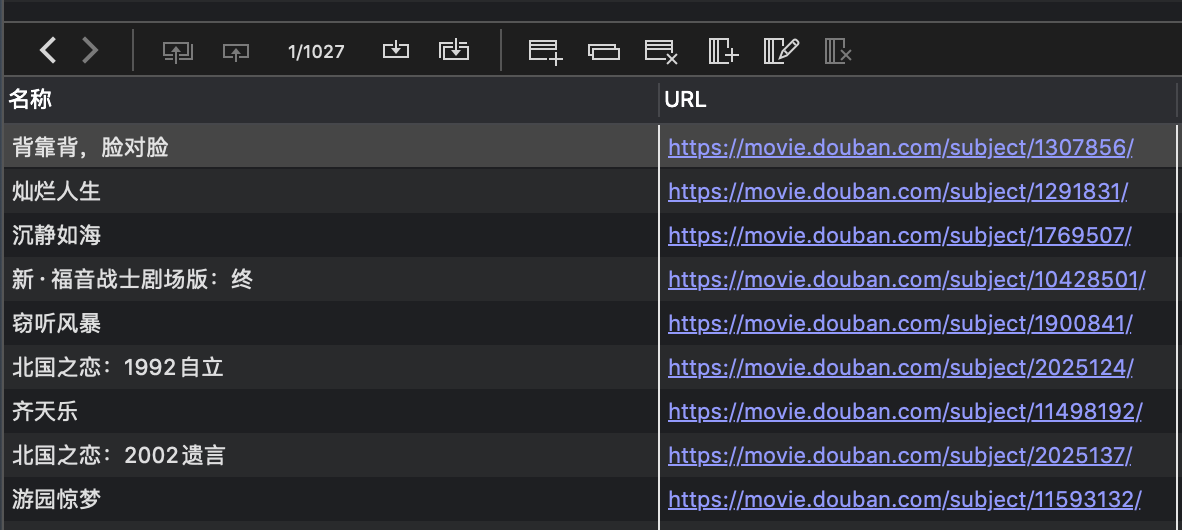
上次在小众软件提问,如何导出豆瓣高分电影,之后通过脚本导出为一个CSV了
CSV的记录在devonthink是这样:
我想每条记录转换成单个RTF文档,每个RTF的标题就是名称+URL的结合,如下图:
至于为什么搞成单个RTF?因为notion太慢太麻烦,转换成单个RTF易于整理,devonthink本身带有元数据库。
这是CSV的文档
链接: https://pan.baidu.com/s/1sh_idVwtlONg_F3X_jWyfg 密码: pdco
–来自百度网盘超级会员V6的分享
montaus
(montaus)
2
问题也可以定义为,一个记事本有100行记录,如何转换成100个txt/rtf,且txt/rtf的文件名为100行记录的内容。
我想起了终端,好像mk还什么命令,可以批量创建文件
我先简单测试一下Notion的效果
把csv导入Notion的database,再导出来
可以批量导出成markdown文件,但是文件名字有点乱码
尝试表格工具+Obsidian插件refactor
使用Notion或Excel等表格工具
先给表头和元数据加上格式信息
我这里测试就只给电影名称加了一个「一级标题 #」,其他元数据可以按需加,用表格工具的公式
使用Obsidian,安装插件note-refactor-obsidian
把数据在表格整理成这样,再粘贴到Obsidian中的一个文档中
(我这里处理得比较粗糙)
运行插件,按照一级标题拆分
就得到了一大堆markdown文件
这个方案在理论上讲是可以很好实现需求的
(已删减,原先插图太多)
思路
制作数据
Notion 的公式:
做一栏代表文件名
做一栏代表网址
做一栏代表元数据:分数
拷贝到文本编辑器中
用正则表达式查找替换,预处理完毕
Obsidian 插件 refactor
一键搞定
突然想起来文件标题不能有这种特殊字符: /,不知道还能不能实现楼主的需求了
再用pandoc把markdown转成RTF
还可以用renamer再改改名(renamer支持表格,有表格在手,数据什么的都好说)
这套流程看起来很折腾,但我自己5分钟搞定
(已删减,原来的图片太占版面了)
需要 Python 3.6+
import csv
from sys import platform
def main():
print("begin")
with open('data.csv', 'r', encoding="utf8") as csvfile:
reader = csv.reader(csvfile)
next(reader) # skip header
for row in reader:
title, url = row[0], row[1]
if platform == "win32":
# escape filename
url = url.replace('/', '-').replace(':', '-')
with open(f"{title} {url}.rtf","w") as f:
pass
print("done")
if __name__ == "__main__":
main()
1 个赞
这曲折的办法太魔性了.
而且你都求助了, 不能一步到位的求助吗?
notion 有数据库啊.
而且最关键的问题是, URL包含:和/, 是不能作为文件名存在的啊.
1 个赞
montaus
(montaus)
8
我在mac,看到代码里有win32,是否要在windows下运行的?
win32 是因为 Windows 下文件名不能有一些特殊符号,所以做了替换。这里的报错是因为没有在你 Finder 打开的 douban 文件夹下运行,要先 cd 过去。
需要把这个 Python 脚本重命名为 csv 之外的其他名字,否则会和 Python 的内置库冲突。
montaus
(montaus)
12
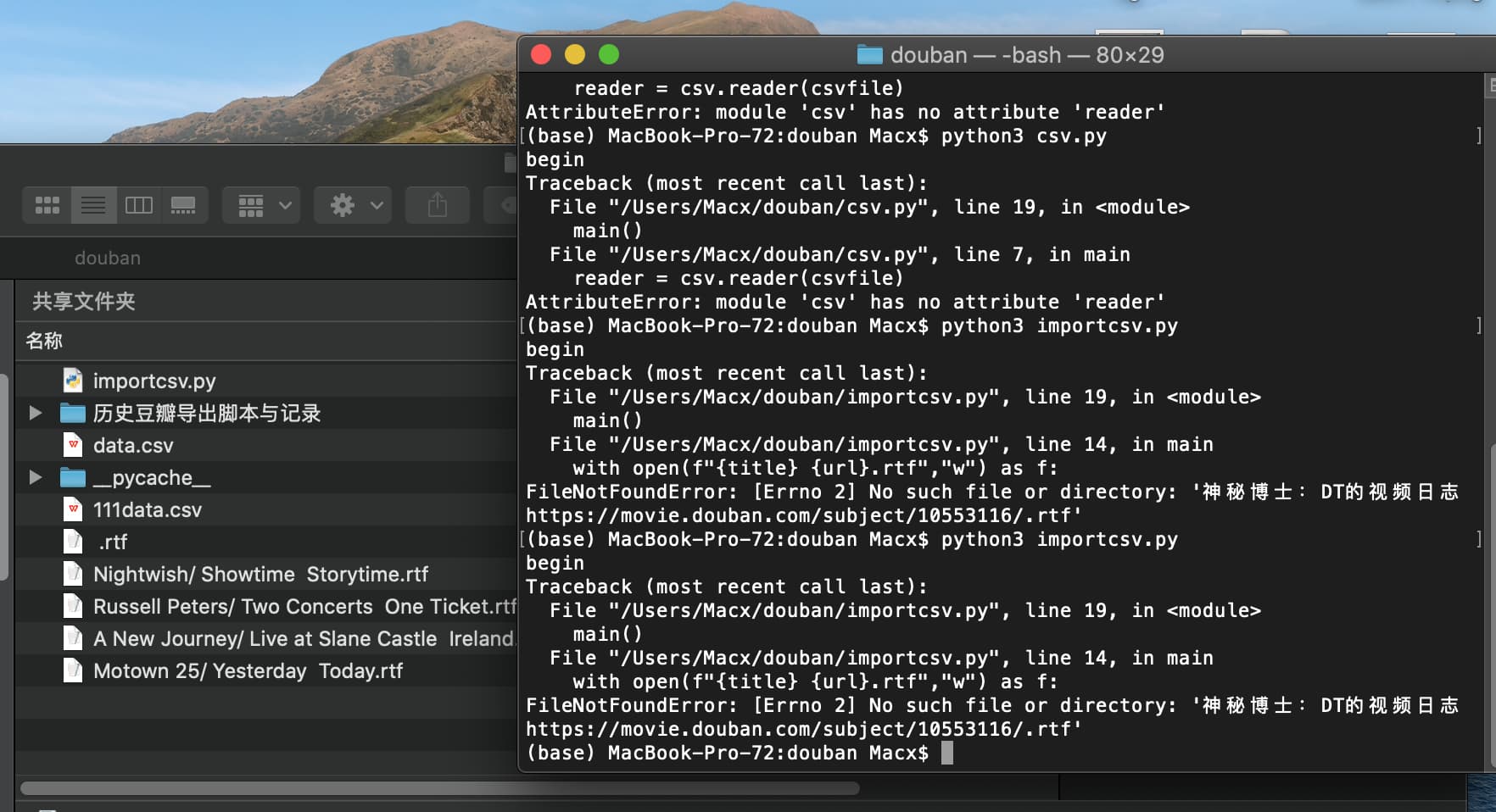
执行到这里,出现了错误
是不是网址里包含了不能作为文件名的符号?
FileNotFoundError: [Errno 2] No such file or directory: ‘神秘博士:DT的视频日志 https://movie.douban.com/subject/10553116/.rtf’
抱歉,手头没有 Mac 设备可供尝试。怀疑你的猜测是正确的。可以试试将脚本里 if platform=="win32:" 改成 if True,强制进行特殊符号替换试试。
montaus
(montaus)
14
我修改了,但是运行出错:
我后面测试了一下,主要的特殊符号是:号,因此,只要去掉网址的前面的https就可以了,脚本可以修改为去掉https://吗?谢谢 @jerrylus
是我没说清楚,11 行应该修改为
if True:
少了一个冒号
以及如果你要去掉 https:// 的话,url = url.replace('/', '-').replace(':', '-') 改为 url = url.replace('https://','').replace('/', '-').replace(':', '-')
这一串 replace 本质上就是替换,参数分别是被替换内容和替换后内容,看你的需要增删就行了