之前有一个老哥说需要类似的功能,我这两天恰好在做类似的东西,就随手写了一个。
项目地址:
https://github.com/diandianti/phpto
两种分类模式:聚类 和 比对, 使用方式可以查看readme
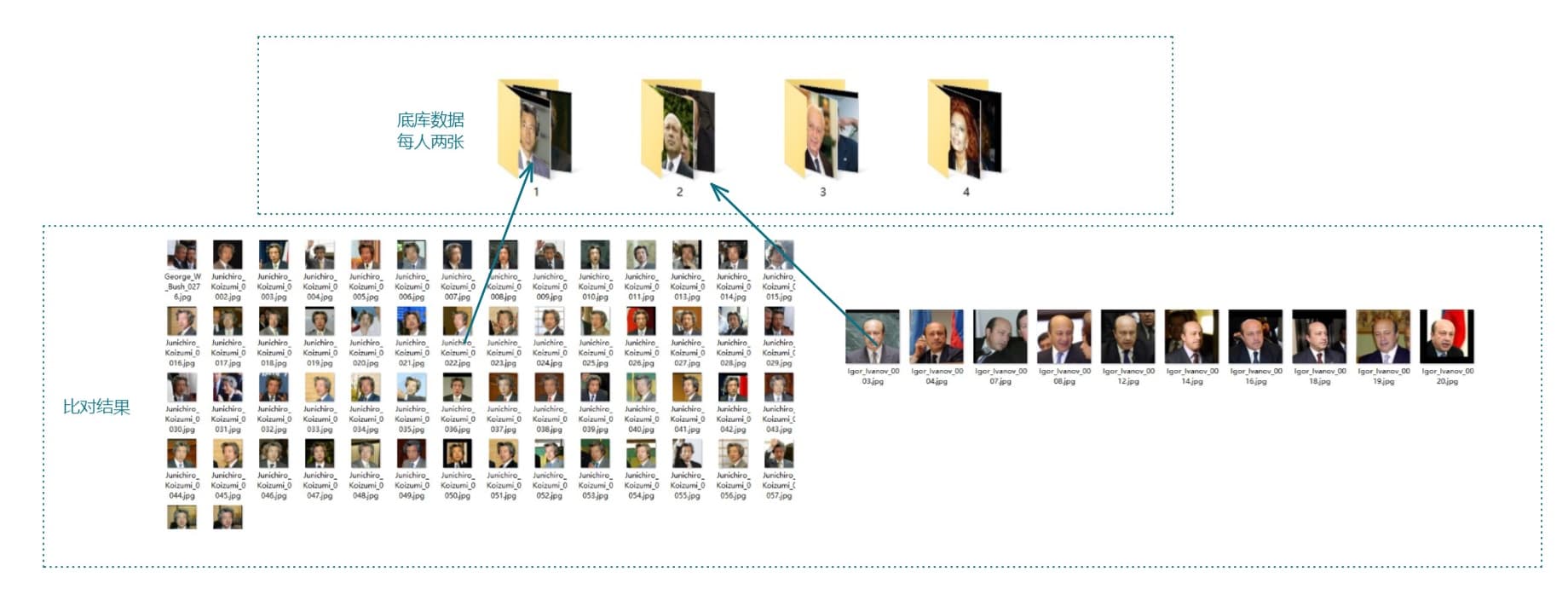
比对效果图
之前有一个老哥说需要类似的功能,我这两天恰好在做类似的东西,就随手写了一个。
项目地址:
https://github.com/diandianti/phpto
两种分类模式:聚类 和 比对, 使用方式可以查看readme
比对效果图
加上了人脸对齐,准确度好了不少
1, data_test/038/038_2.bmp
1, data_test/038/038_4.bmp
1, data_test/038/038_3.bmp
1, data_test/038/038_0.bmp
1, data_test/038/038_1.bmp
2, data_test/084/084_1.bmp
2, data_test/084/084_4.bmp
2, data_test/084/084_3.bmp
2, data_test/084/084_2.bmp
2, data_test/084/084_0.bmp
3, data_test/059/059_2.bmp
3, data_test/059/059_3.bmp
3, data_test/059/059_0.bmp
3, data_test/059/059_4.bmp
3, data_test/059/059_1.bmp
先贴上库,剩下的以后再补充
厉害了。
readme已经补充,已经换了win10进行测试,我这里看起来没啥问题。
正好弄这方面的,顺手写了一个
19:25整个zip下载的,需要重新下载吗?
还是仅仅补充了readme?
根据每次报错pip安装了模块,最后运行的结果是:
Z:\p\phpto-main>python process.py
NAME
process.py
SYNOPSIS
process.py COMMAND
COMMANDS
COMMAND is one of the following:
cluster
代码改了一小部分,你可以git pull来更新一下,不改关系也不大,就是可能会有点慢
命令如下
python process.py cluster /path/to/photos --do_copy=True --dst=/path/to/copy/photo --out=res.txt
其中do_copy和dst是可选的,表示把照片复制到一个新的文件夹中
处置完成之后会生成一个res.txt的文件
谢谢,那还是再取一下吧。。。。
models下面的文件占了99%的容量,这里面是网络的权重,如果方便,git pull会快很多,全部重新下可能会比较慢。
哦,只在一个文件注释掉一行。。。。
还好今天github下载速度挺快,只是时不时又刷不出。
对同一个的照片目录执行多遍,每次都是重新分析全部的?
如果能知道哪些照片是分析过的,自动跳过就会快很多。
不过,这个倒不太严重,每次为新照片建个新目录给它分析 就行了。只是这次(只分析新照片)的结果txt会与上次的txt合并起来(在上次的txt里追加新出现的人;上次的人在新照片出现,也追加 旧id=新照片路径)吗?现在是覆盖同名txt(上次分析的旧人和旧照片 都清空了)?
每张图片都只做一次fd的检测和若干次fr的推理(这个若干次取决于图片内人脸的数目)
多次比对是为了计算不同图像之间的距离,这个速度比较快。
两次对一个目录的分析,其实和单次处理的结果是一样的,如果out的命名一样就会将之前的文件覆盖,上一次复制的图像会不会被覆盖,新加入的图像会放进和老的图像相同id的文件夹。
多次处理的记录还没有加入,但是程序有cache机制,但是相关的功能还没写完。
应该还有一些其他的问题,后续慢慢完善和填补吧
【新加入的图像会放进和老的图像相同id的文件夹】
运行了几次,在程序目录及照片目录没有看到 新增的文件或目录啊?
追加处理的机制 可能是比较复杂了。。。。
原来以为是:
每个人脸会分配一个id=它的特征值
每张照片里的人脸,也算出各自的特征值,再与人脸id之后的值比较。。。。
这个地方建议做一个聚类分析 谱聚类就差不多够用了
看的我也搓了一个出来……
Foolish_album
63%|██████████████████████████████████████████████████ | 179/286 [00:51<00:37, 2.86it/s]
在这里卡住了,cpu也不占用了
63%|██████████████████████████████████████████████████ | 179/286 [01:09<01:00, 1.75it/s]
中断了第二次执行,也是这样
6666
减少一点图像试试呢,或者一直跟踪一下程序使用的内存,难道是内存占用太多被kill了
两位老哥这么晚还不睡
现有的聚类分析需要耗费![]() 一点点时间,现在做的也算是一种聚类了
一点点时间,现在做的也算是一种聚类了 ![]()
(其实是根本没有调研聚类算法在人脸分析上面的效果![]() )
)
可能是某一张图太大了? 我又更新了一版 你也看一下按名称排序的第179张是不是有些问题