TXT文件每行文字如果少于5个字符,则删除整行
在吾爱上面找了一个py写的,试用之后生成的是0kb空文件,请问还有其他软件吗
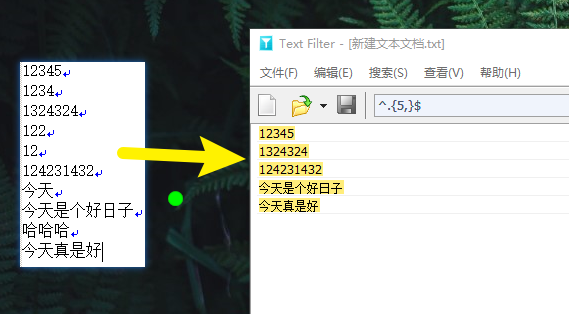
TextFilter
开启正则匹配,然后输入这段进行筛选就好了,然后保存筛选结果就是了
^.{5,}$
批量处理的话,我用的是
水淼·文件批量处理器
https://www.shuimiao.net/FileBat/
1 个赞
请给出源代码。
待处理文件:test.txt
1234
12345
123456
123456
123456
123456
123456
123456
123456
123456
1234567
1234567
1234567
1234567
1234567
1234567
给出脚本:test.py
#!/usr/bin/python3.9
fi = open('test.txt', 'r')
fo = open('output.txt', 'w')
lis = fi.readlines()
lis_output = []
for line in lis:
if len(line.strip()) >= 5:
lis_output.append(line)
print(lis_output)
for line in lis_output:
fo.write(line)
fi.close()
fo.close()
得到结果文件:output.txt
12345
123456
123456
123456
123456
123456
123456
123456
123456
1234567
1234567
1234567
1234567
1234567
1234567
按行读取时,行末的换行符也会被算做一个字符:
>>> len('1234')
4
>>> len('1234\n')
5
不用那么复杂吧~导入到excel,然后设一个结果列,用len函数判断文本长度,超出的就输出空白字符串,然后把结果列仅值复制到新表再另存为为txt(或者直接复制出来?)即可。
可能会有些行首尾的双引号需要处理,那么用word替换^p"和^p"为空白即可。
1 个赞
VSCode 中也可以使用正则匹配
^.{0,4}$\n
Alt + Enter 键快速选中匹配文本,再进行删除
1 个赞
支持正则的文本编辑器,就是一个替换的事情啊。^.{0,4}$ 替换成空,如果还有空行,再删除空行。

能少打几个字,windows下测试的
type input.txt |awk “length($0) >5” > output.txt
如果是依靠已有软件, 且不增加学习难度的话 :
推荐 excel 或 wps里的ET.
如楼上 @deanme 的方法即可.
如果会c#, 直接运行以下代码:
using System;
using System.IO;
namespace ConsoleApp1
{
class Program
{
static void Main()
{
Console.WriteLine("请输入要读取的文本文件路径,比如(D:\\1.txt)");
string file = Console.ReadLine();
if(File.Exists(file))
{
StreamReader sr = new StreamReader(file);
string line;
while ((line = sr.ReadLine()) != null)
{
if(line.Length>=5) Console.WriteLine(line);
}
}
else
{
Console.WriteLine(file+ "不存在!");
}
Console.WriteLine("按回车程序将退出!");
Console.ReadLine();
}
}
}
三剑客还是awk直观
grep -vP “^.{0,4}$" input.txt
sed -Ee "/^.{0,4}$/d” input.txt
awk “length($0)>4” input.txt
grep、sed应该很强大了,但
1、能不能 存储前面特定条件行获得的某些信息,再在后面行里使用?
比如把dos内部命令dir的输出(如后面的例子)变成每行 datetime size path\filename.ext 格式。因为path只会在前面出现一次,后面的文件就都不带path了。
如果dir直接有参数支持这种模式就最好了(/b、/w接近了,但没有 datetime size了)
2、能不能检测出异常的行:正常应该 文件名的前3位就是目录名。
Directory of E:\jpg\034
2022-06-06 02:51 <DIR> .
2022-06-06 02:51 <DIR> ..
2022-06-05 02:32 95108 03421.001.jpg
2022-06-05 02:32 99557 03421.002.jpg
2022-06-05 02:32 93005 03421.003.jpg
2022-06-05 02:32 98310 03421.004.jpg
2022-06-05 02:32 109921 03421.005.jpg
2022-06-05 02:32 89824 03421.006.jpg
2022-06-05 02:32 105422 03421.007.jpg
7 File(s) 691147 bytes
Directory of E:\jpg\036
2022-06-05 03:44 <DIR> .
2022-06-05 03:44 <DIR> ..
2022-06-05 02:43 62526 03613.037.jpg
1 File(s) 62526 bytes
Directory of E:\jpg\046
2022-06-05 03:44 <DIR> .
2022-06-05 03:44 <DIR> ..
2022-06-05 03:01 65942 04631.001.jpg
2022-06-05 03:01 125628 04631.002.jpg
2022-06-05 03:01 117474 04631.003.jpg
2022-06-05 03:01 97649 04631.028.jpg
2022-06-05 03:01 101486 04631.029.jpg
2022-06-05 03:01 86077 04631.030.jpg
2022-06-05 03:01 67794 04631.031.jpg
2022-06-05 03:01 179303 04631.039.jpg
2022-06-05 03:01 140773 04631.040.jpg
2022-06-05 03:01 75709 04631.041.jpg
2022-06-05 03:01 65038 04631.046.jpg
2022-06-05 03:01 81197 04631.047.jpg
2022-06-05 03:01 79287 04631.048.jpg
13 File(s) 1283357 bytes
1倒是可以利用everything的导出结果
2只能导入数据库后再用sql查询
看看这是不是你要的效果?
1、
for /f %i in ('dir /a-d /s /b') do @echo %~ti %~zi %i
2、
for /f %i in ('dir /AD /b') do @(dir %i /s /b)|find /V "%i\%i"
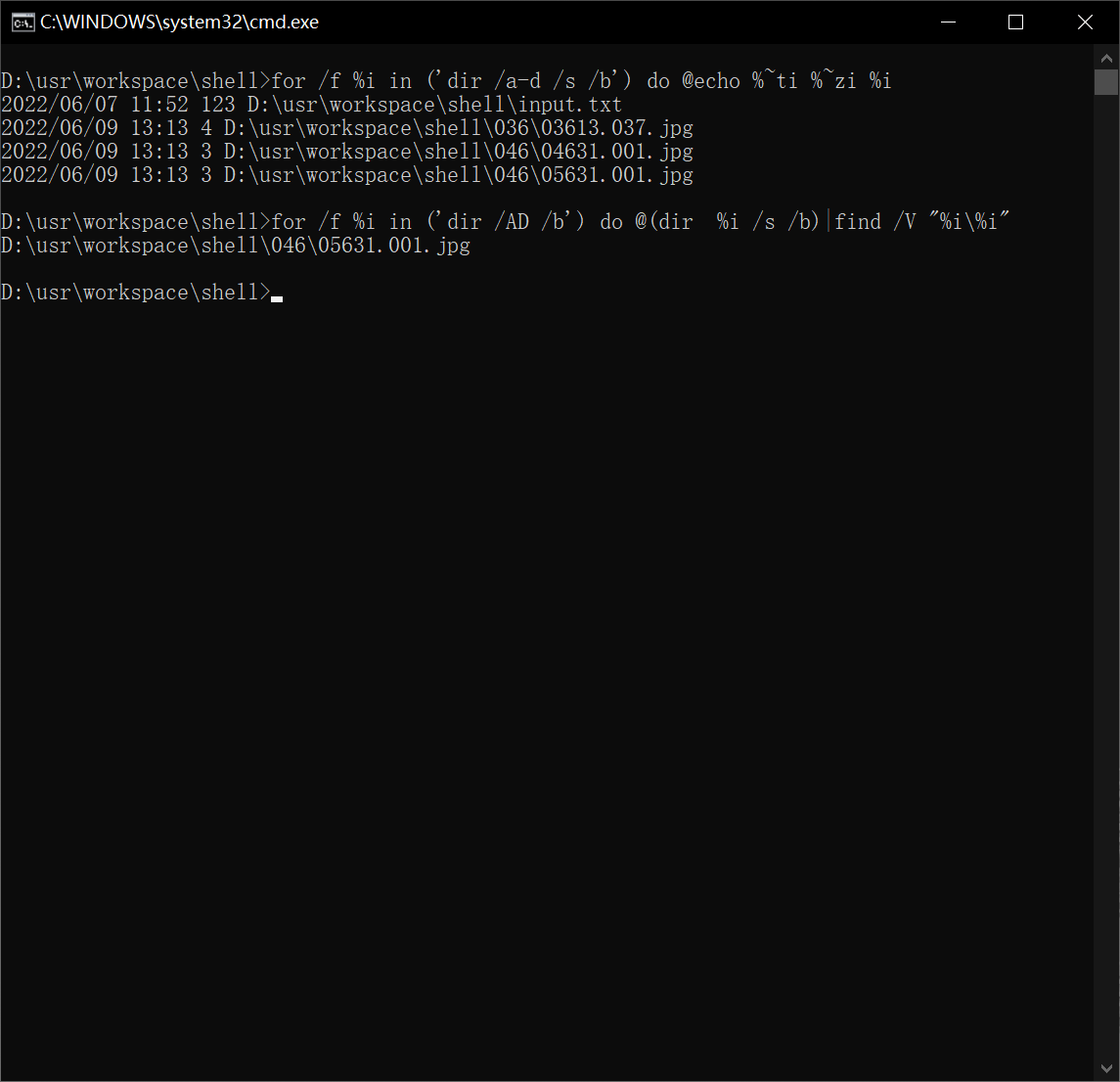
应该是足够了,看来dos命令也能做到。只是
1的for /f把每个文件都分别取一次文件信息
2的每个文件都分别dir一次
,会不会慢很多?
sed看来也是没有这种 跨行取内容给后续行使用 的机制。。。。
将输出信息当做文本来处理满足需求,逻辑上更清晰,但是实现上可能会相当麻烦,sed有寄存器,用h或H保存模式匹配到寄存器,g或G获取,属于sed的高难命令,相当不好理解。用这个思路重新来实现一下需求,sed命令已经很难阅读了。
1、
dir /a-d /s|sed -re "/\\jpg\\/{s/([^ ]*\\jpg\\[^ ]*)/[\1]/;s/.*\[//;s/\].*//;h};/^[0-9]{4}/{G;s/([^ ]*)\n(.*)/\2\\\1/;p};d"
2、
dir /s /A-D /b |grep -P -v "([0-9]+)\\\1"

还真的能处理啊?
正则每次都需要重新查,复杂的更加。。。。。
我的grep还是Turbo GREP 5.5 Copyright (c) 1992, 1999 Inprise Corporation
Syntax: GREP [-rlcnvidzuwo] searchstring file[s] or @filelist
GREP ? for help
-P都不支持。。。
sed还没找
打算everything导出csv,再导入sqlite,由程序对同字节的文件补充 文件头字段、CRC32字段(跳过前24字节,有些图片完全一样,就是这里不一样,也应该算同一个内容)
这个帖子真赞,居然这么多方法
可以用 chocolatey 安装一下,非常省心。
上次想安装与它并列的包管理工具,结果需要powershell高版本,而win7怎么也无法让ps更新到这个版本。。。。
就不能简简单单下载、解压缩就能用
老马软件里面的TextForever,用了十多年的文本处理软件,一直在升级更新,功能非常强悍,可以试一试,这是他的博客 strnghrs - 博客园