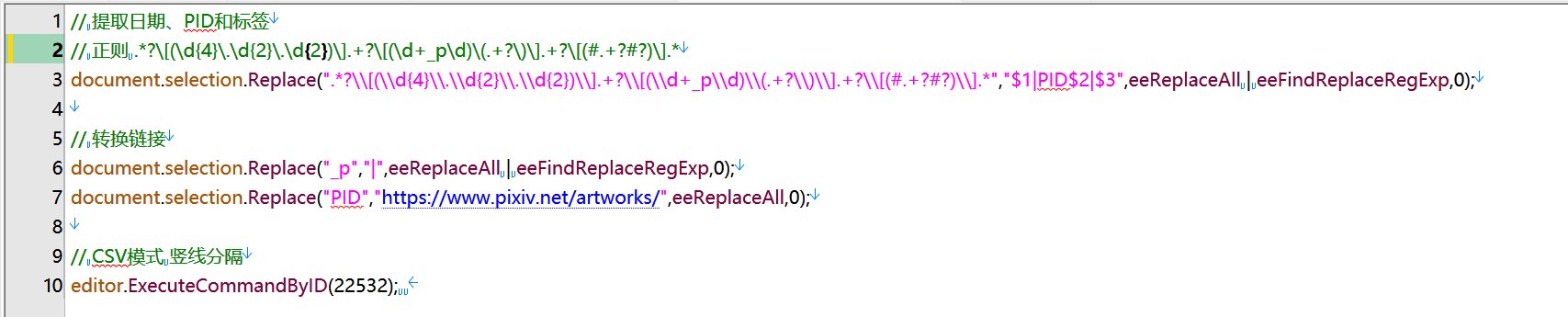
您这个问题可以用 busybox-w32 里面的UNIX命令行工具解决。
我们先将原始数据保持在 data.txt 中。
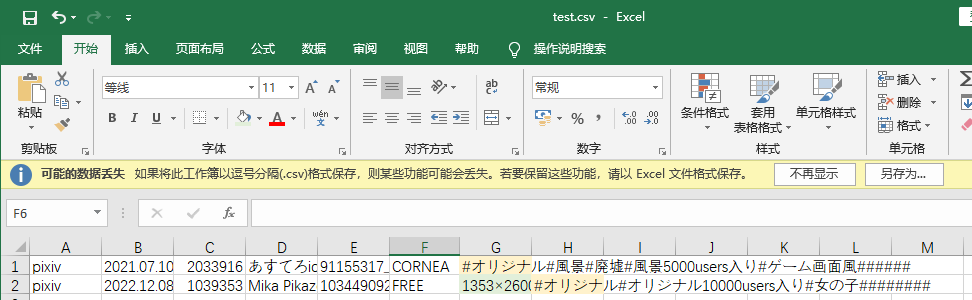
首先,您给出的这段数据,如果将其中的所有 [ 和 ) 删去,并将所有 ] 和 ( 替换为 , ,则可得到一张二维表:
sed -e 's/\[//g; s/\]/,/g; s/(/,/g; s/)//g' data.txt > data.csv
效果如下:
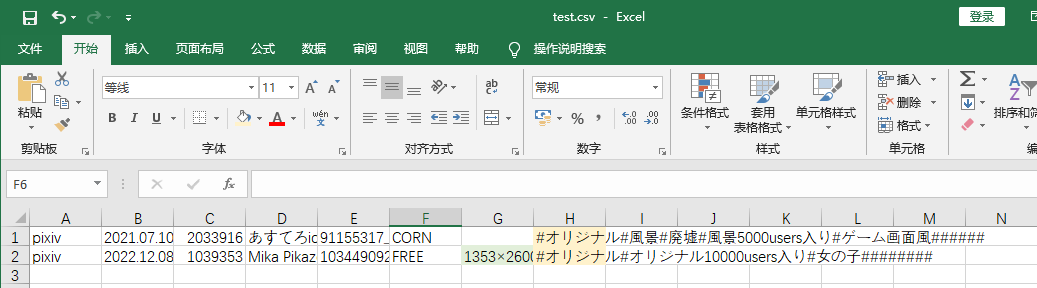
不过很显然,第1行没有分辨率信息,故会出现串行。为此要将前面是大写字母的 ,# 替换为 ,,#,即为分辨率信息留出空的单元格:
sed -E -i 's/([A-Z])([A-Z])\>,#/,,#/g' data.csv
这里参考了 https://blog.csdn.net/u011584949/article/details/126933992
效果如下:
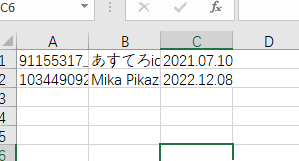
剩下的就好办了,把每一列提取出来,再将您感兴趣的列拼接在一起即可。
按列分析文本是 awk 的看家本领。可如我们要提取 “日期”、“画师名” 和 “插画ID” 两列(即第2列、第4列和第5列),可以这样做:
awk -F ',' '{print $2}' data.csv > date.list
awk -F ',' '{print $4}' data.csv > artist.list
awk -F ',' '{print $5}' data.csv > pic_id.list
然后,将这些文本以 , 为分隔符,按列拼接,即可得到一个 csv 表格。这是 paste 工具擅长的。命令如下:
paste -d ',' pic_id.list artist.list date.list > pic_data.csv
其中,-d 选项用于指定分隔符,> 符号前的文件排列顺序,就是输出文档中各列的顺序。
综上,可写成如下脚本:
#!/bin/sh
# 数据预处理
sed -e 's/\[//g; s/\]/,/g; s/(/,/g; s/)//g' data.txt > data.csv
sed -E -i 's/([A-Z])([A-Z])\>,#/,,#/g' data.csv
# 剥离列
awk -F ',' '{print $2}' data.csv > date.list
awk -F ',' '{print $4}' data.csv > artist.list
awk -F ',' '{print $5}' data.csv > pic_id.list
# 列重组
paste -d ',' pic_id.list artist.list date.list > pic_data.csv
# 清理临时文件
rm data.csv
rm *.list
在WIndows下,可将上述命令保存为脚本文件 script.sh,然后安装 busybox-w32(官网:https://frippery.org/busybox/):下载 busybox.exe(或 busybox64.exe·,用于64位系统),将其放在 X:\Windows` 目录下(X 是系统盘盘符),然后在命令行中执行:
busybox ash ./script.sh
# 或:busybox64 ash ./script.sh
不过,这样得到的 csv 文档是以 UTF-8 编码的,在Excel上读取时可能会出一些问题(我用的是Office 2019,读取 UTF-8 编码的 csv 文档时会乱码,可能是我的配置不正确)。
如想进一步了解awk,可以看一看这篇文章:https://www.ruanyifeng.com/blog/2018/11/awk.html。awk是一门强大的、用于数据分析的计算机语言,但其基本操作还是很简单的。
sed也是一个不错的编辑器,很适合在脚本中使用,其基本操作可以参考这篇文献:http://c.biancheng.net/view/994.html