有个一批量打印工具BulkPrinter很好用,但是不能统计每次打印了多少页。
有没有办法能统计一批文档一共有多少页呢?
提供一个间接统计的思路:先将文档用虚拟打印机批量打印为一个PDF文档,再看一看输出的PDF文档的页数。既然BulkPrinter支持同时打印多种不同格式的文档,那么用这个方法应该也可以同时统计多种格式文档的总页数。
先安装 pdfFactory,用免费版本的就够用。安装后启动 pdfFactory。
https://www.pdffactorychina.cn/xiazai.html
然后打开 BulkPrinter,打印机选择 “pdfFactory”,并点击 “Start Printing”。
最后切换到 pdfFactory 窗口,按住滚动条,即可看到本批次一共打印了多少文档。
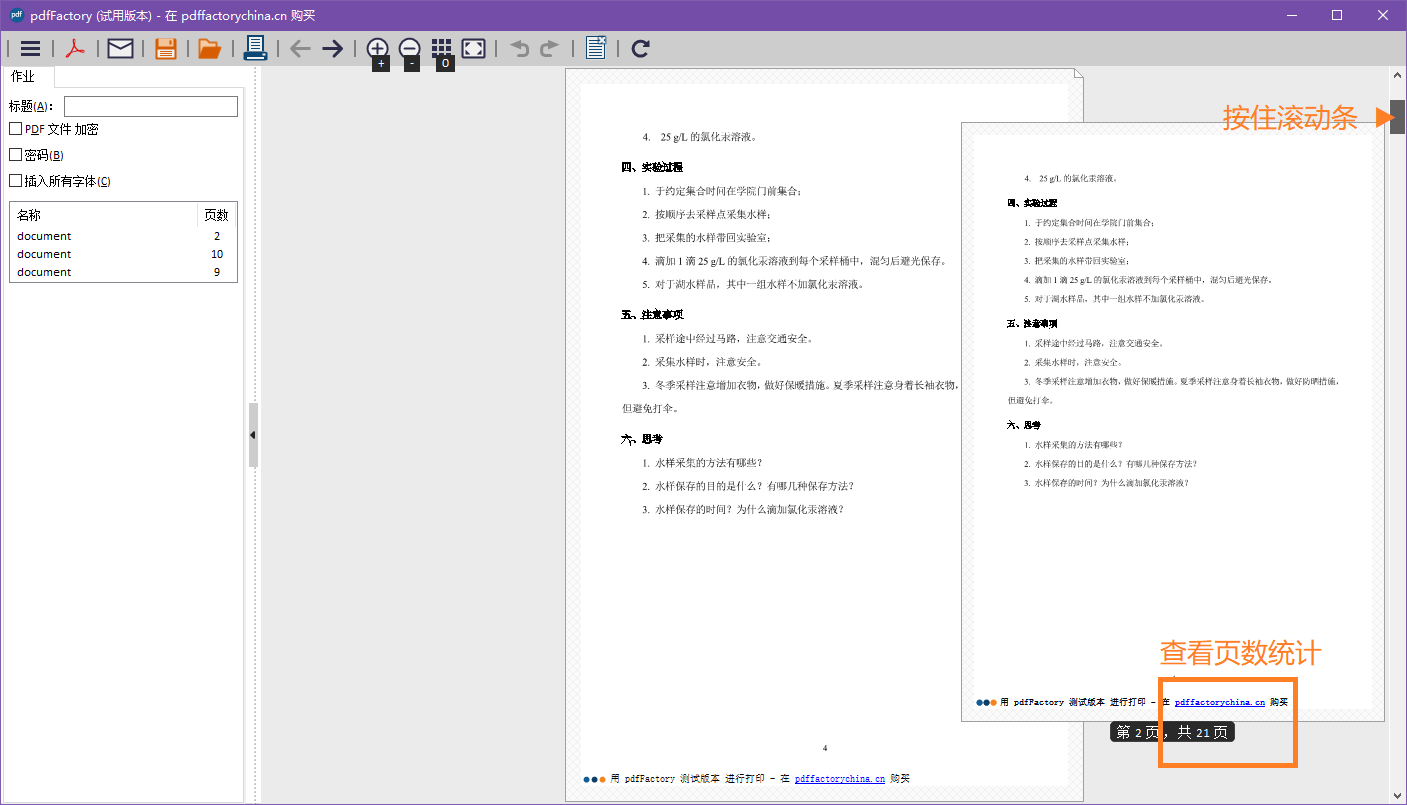
操作结束后,关闭 pdfFactory软件,查看 “用户文件夹\文档\Pdf files” 文件夹内的内容,这是 pdfFactory 虚拟打印机输出的文档。如无需要,可将其删除。
pdfFactory 和 Microsoft Print To PDF很相似,支持自动保存文档,以及将同一批次打印的文档保存为一个PDF,但其输出的文档中会有水印。
PDF:https://www.zhihu.com/question/386818964
Word:文件夹使用详细信息的试图,右键文件夹上方的标签,其他,勾选页码范围,然后可以截图页码范围的一列,微信提取文字到excel里面求和。当然也有powershell能统计,不过也就麻烦了
我尝试过打印为PDF,但也只是每个文档打印成一个pdf文件,没法统计总页数
不只是word,还有pdf的
pdfFactory 的虚拟打印机可以将同一批次打印的文档保存为一个PDF文件。
谢谢,一会我去试下
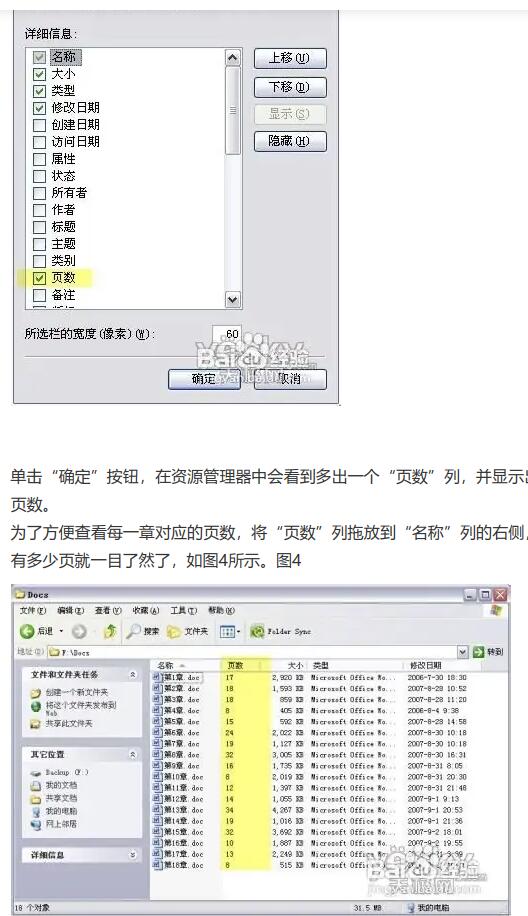
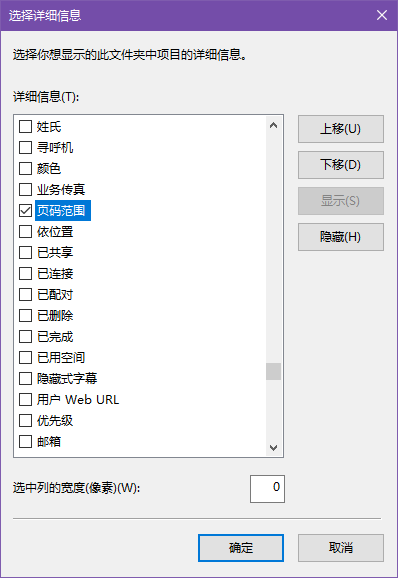
我试过了,"页码范围"一点都不准确
试试这个 python 脚本吧。
使用前请先到 Microsoft Store 中安装 Python,再按 Win + X,点击 “命令提示符 (管理员)” 或 “Windows Powershell (管理员)”,执行如下命令,安装所需的 Python 库:
pip install pdfplumber -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pypiwin32 -i https://pypi.tuna.tsinghua.edu.cn/simple
此外,本方法需要电脑上安装有 Microsoft Word。
以下是代码:
import os
import pdfplumber
import math
from win32com.client import Dispatch
from pdfminer.pdfparser import PDFSyntaxError
def get_word_page(word_path):
word = Dispatch('Word.Application')
word.Visible = False
word = word.Documents.Open(word_path)
word.Repaginate()
num_of_sheets = word.ComputeStatistics(2)
return num_of_sheets
def get_pdf_page(pdf_path):
try:
f=pdfplumber.open(pdf_path)
page=len(f.pages)
except PDFSyntaxError:
page=0
return page
page_sum = 0
cost_sum = 0
number_of_docx = 0
number_of_doc = 0
number_of_pdf = 0
page_of_docx = 0
page_of_doc = 0
page_of_pdf = 0
cost_of_docx = 0
cost_of_doc = 0
cost_of_pdf = 0
l=os.listdir('.')
for file in l:
if file.endswith('.docx'):
docfile=f"{os.getcwd()}/{file}"
docfile=docfile.replace("\\","/")
p=get_word_page(docfile)
number_of_docx+=1
page_of_docx+=p
cost_of_docx+=math.ceil(p/2)
if file.endswith('.doc'):
docfile=f"{os.getcwd()}/{file}"
docfile=docfile.replace("\\","/")
p=get_word_page(docfile)
number_of_doc+=1
page_of_doc+=p
cost_of_doc+=math.ceil(p/2)
if file.endswith('.pdf'):
p=get_pdf_page(file)
number_of_pdf+=1
page_of_pdf+=p
cost_of_pdf+=math.ceil(p/2)
page_sum=page_of_doc+page_of_docx+page_of_pdf
cost_sum=cost_of_doc+cost_of_docx+cost_of_pdf
print("统计报告")
print("当前目录下,有:")
print("docx 文档")
print(" 文件个数:", number_of_docx)
print(" 总页数:", page_of_docx)
print(" 如双面打印,须消耗纸张数:", cost_of_docx)
print("doc 文档")
print(" 文件个数:", number_of_doc)
print(" 总页数:", page_of_doc)
print(" 如双面打印,须消耗纸张数:", cost_of_doc)
print("pdf 文档")
print(" 文件个数:", number_of_pdf)
print(" 总页数:", page_of_pdf)
print(" 如双面打印,须消耗纸张数:", cost_of_pdf)
print("小结")
print(" 文件总页数:", page_sum)
print(" 如双面打印所有文档,须消耗纸张数:", cost_sum)
input("按 Enter 退出。")
- word文档的读取参考了 https://www.sci.dog/?p=744
- PDF文档的读取参考了 https://blog.csdn.net/Twinkle_sone/article/details/116004031
将前文给出的 Python 代码保存为 count.py ,放在要统计的文档所在的文件夹下,双击即可运行。
P.S. 这里面的 “双面打印,须消耗纸张数” 是这样计算的:假如某文档的页数为奇数,那么打印该文档时,其最后一页也会占用一张纸。
换言之,双面打印文档时,消耗纸张数等于文档页数除以2,再向上取整。
假如我们要打印两份文档,每份文档都是3页,那么消耗的纸张数就是 ceil(3/2)+ceil(3/2)=2+2=4 张,而非 (3+3)/2=6 张。
稍稍调整了下代码,程序运行后按 Enter 才会退出,不会一闪而过。
刚才试了一下,这段代码统计的是文档的段落数,不是页数。
感谢大家,但我只是想有个简单的方法

如果能接受付费方案的话可以试试 PageAID,支持Word文档、Excel电子表格、PPT以及PDF文档,不过价格不菲,大约为人民币 69元。
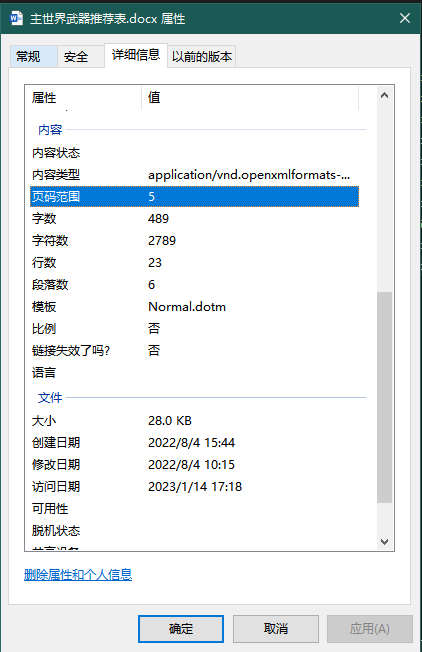
文件夹中直接显示PDF页数,排序 - 知乎 (zhihu.com)
首先安装上文链接里的显示pdf页数的工具:
效果如下:
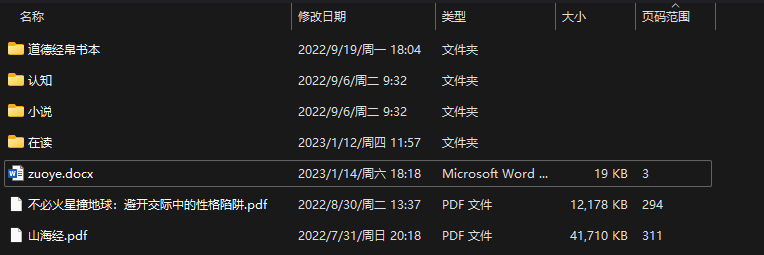
第二部,通过一个小工具:
SysExporter: Grab data from list-view, tree-view, combo box, WebBrowser control, and text-box. (nirsoft.net)
可以直接提取文件管理器的当前页面内容:
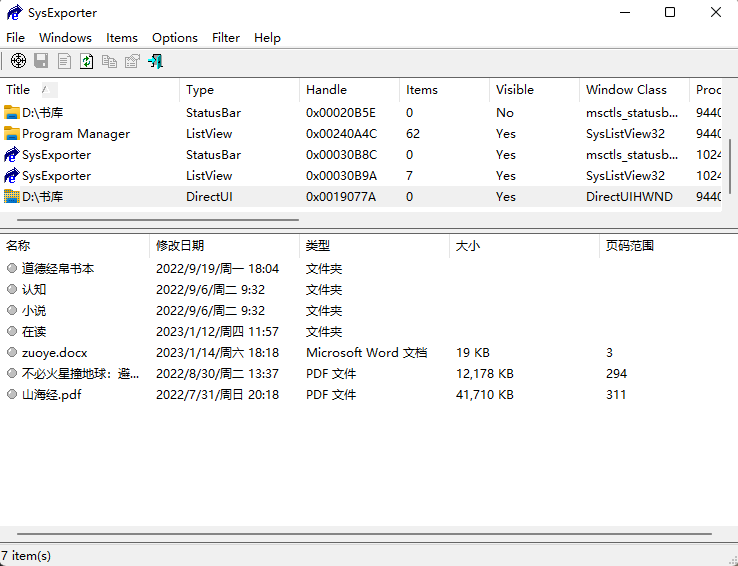
在下方区域右键,通过choose columns筛掉其他项目,然后再右键进行html report
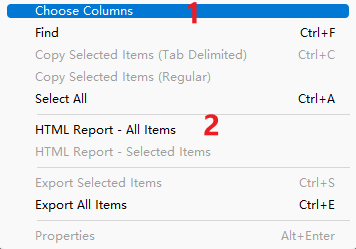
得到一个表格:
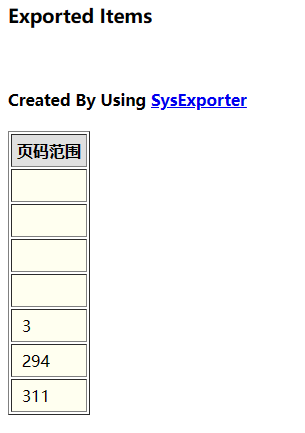
然后再把表格复制到excel里sum一下就哦了~
====
第一次操作可能费劲点,但是会了之后每次只用不到一分钟就能搞定~
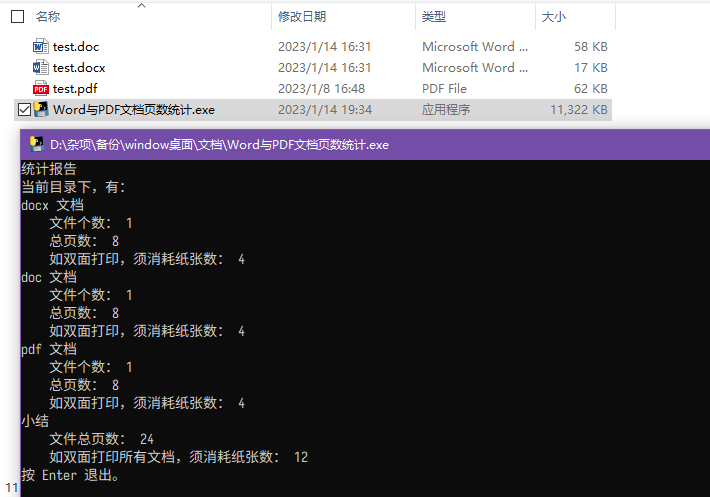
代码调整了一下,编译成了 exe 可执行文件。下载这个 exe 可执行文件,和要统计页数的文档放在同一文件夹下,然后双击运行即可。
本程序使用 pyinstaller 打包生成,是64位程序,打包后使用 Windows Defender 扫描,未发现威胁。
- 下载链接:https://wwba.lanzoum.com/ilMnh0l0407i
- 密码:h5ta
- SHA256:134716f4adc97a5bbb7ef94ec898f233807ff88b0186fe54b5d97590fca0a5af
- 平台:AMD64
- 软件截图:
修改后的代码为:
import os
import math
from win32com.client import Dispatch
from PyPDF3 import PdfFileReader
def get_word_page(word_path):
word = Dispatch('Word.Application')
word.Visible = False
word = word.Documents.Open(word_path)
word.Repaginate()
num_of_sheets = word.ComputeStatistics(2)
return num_of_sheets
def get_pdf_page(pdf_path):
filename = pdf_path
reader = PdfFileReader(filename)
if reader.isEncrypted:
reader.decrypt('')
page = reader.getNumPages()
return page
page_sum = 0
cost_sum = 0
number_of_docx = 0
number_of_doc = 0
number_of_pdf = 0
page_of_docx = 0
page_of_doc = 0
page_of_pdf = 0
cost_of_docx = 0
cost_of_doc = 0
cost_of_pdf = 0
l=os.listdir('.')
for file in l:
if file.endswith('.docx'):
docfile=f"{os.getcwd()}/{file}"
docfile=docfile.replace("\\","/")
p=get_word_page(docfile)
number_of_docx+=1
page_of_docx+=p
cost_of_docx+=math.ceil(p/2)
if file.endswith('.doc'):
docfile=f"{os.getcwd()}/{file}"
docfile=docfile.replace("\\","/")
p=get_word_page(docfile)
number_of_doc+=1
page_of_doc+=p
cost_of_doc+=math.ceil(p/2)
if file.endswith('.pdf'):
p=get_pdf_page(file)
number_of_pdf+=1
page_of_pdf+=p
cost_of_pdf+=math.ceil(p/2)
page_sum=page_of_doc+page_of_docx+page_of_pdf
cost_sum=cost_of_doc+cost_of_docx+cost_of_pdf
print("统计报告")
print("当前目录下,有:")
print("docx 文档")
print(" 文件个数:", number_of_docx)
print(" 总页数:", page_of_docx)
print(" 如双面打印,须消耗纸张数:", cost_of_docx)
print("doc 文档")
print(" 文件个数:", number_of_doc)
print(" 总页数:", page_of_doc)
print(" 如双面打印,须消耗纸张数:", cost_of_doc)
print("pdf 文档")
print(" 文件个数:", number_of_pdf)
print(" 总页数:", page_of_pdf)
print(" 如双面打印,须消耗纸张数:", cost_of_pdf)
print("小结")
print(" 文件总页数:", page_sum)
print(" 如双面打印所有文档,须消耗纸张数:", cost_sum)
input("按 Enter 退出。")
之前的代码使用 pdfplumber 库统计 PDF 页数,但使用 pyinstaller 打包时总是出错;这次换成了 PyPDF3,顺利完成了打包。