示例文本如下:
The Stand Off 今早没牛奶!
The Coconut 椰子壳好硬!
The Shepherd 牧羊犬大赛
You Missed a Bit 越帮越忙
Let‘s Spray 涂鸦惊喜
想做到以下效果:(中英文中间,还有一个空格)
今早没牛奶! The Stand Off
椰子壳好硬! The Coconut
牧羊犬大赛 The Shepherd
越帮越忙 You Missed a Bit
涂鸦惊喜 Let‘s Spray
搜索了下,网上提供的教程都是word通配符替换,excel公式修改。但我试了这两种方式,没有效果,不知道是步骤没做对还是怎么回事。所以来论坛求助一下大佬们,希望能有一个更简单的方法,最好是有软件直接提供这个功能的,谢谢。
ai问了两圈就出来了,读取同目录下的data.txt,互换后的内容会保存至同目录的updata.txt下:
import re
# 读取原始数据
with open('data.txt', 'r', encoding='utf-8') as file:
data = file.readlines()
# 中英文互换位置
swapped_data = []
for item in data:
item = item.strip() # 去除行末的换行符
# 使用正则表达式匹配中文字符和非中文字符
chinese_part = re.findall(r'[\u4e00-\u9fa5!?。,]+', item)
english_part = re.findall(r'[^\u4e00-\u9fa5!?。,]+', item)
# 确保匹配结果不为空
if chinese_part and english_part:
swapped_data.append(chinese_part[0] + " " + english_part[0])
else:
swapped_data.append(item)
# 输出结果到文件
with open('updata.txt', 'w', encoding='utf-8') as file:
for line in swapped_data:
file.write(line + '\n')
(需要Python环境)
找个支持正则表达式的文本编辑器,一般都可以做到。
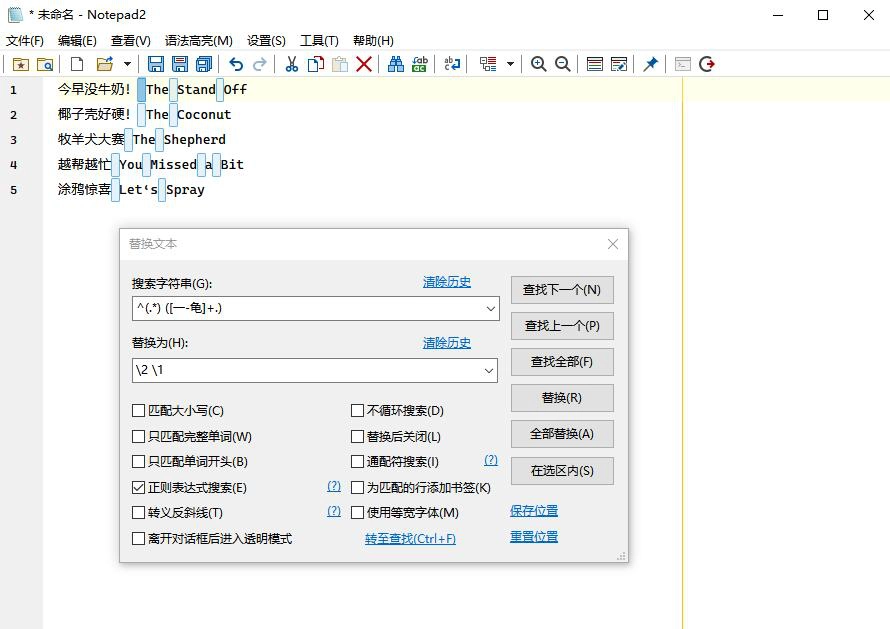
查找:^(.*) ([一-龟]+.)
替换:\2 \1
3 个赞
nilmomo
2024 年7 月 12 日 04:16
5
vscode
(^[a-zA-Z\s.,!?;‘:]*)([\u4e00-\u9fa5\u3000-\u303f\u3040-\u309f\u30a0-\u30ff\uff00-\uffff\u3300-\u33ff\u3400-\u4dbf\u4e00-\u9fa5]+)
$2 $1
(^[a-zA-Z\s.,!?;‘:]*)([一-龟]+.)
$2 $1
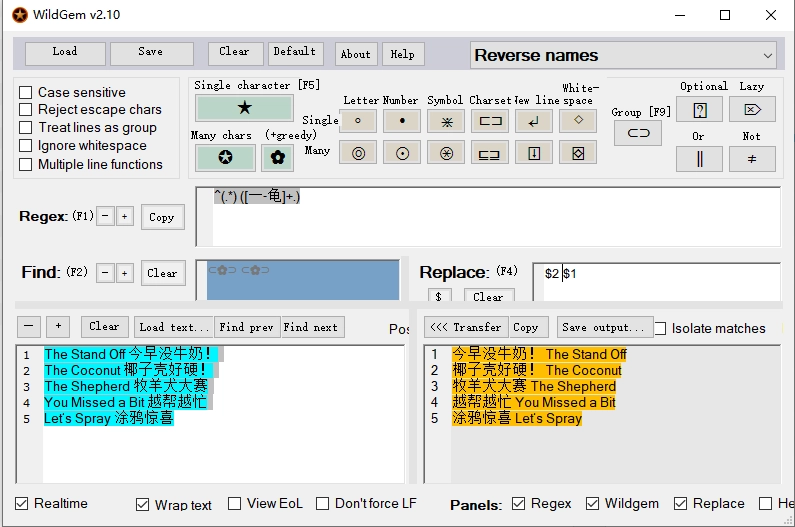
^(.*) ([一-龟]+.)
$2 $1
可以把后面不带空格的中文移动到前面,不需要用正则表达式。
Vim 命令:
:g/./exe 'norm I ' | exe 'norm $F d$0P0x'
用录制按键 更方便,自己把每个指令写下来要测试很多遍。
dms
2024 年7 月 12 日 07:02
7
如果都是示例这种,正则很简单了
^([\w ‘]+?)\s+([^\w]+)$
替换为:
$2 $1
前面是 字母,数字、下划线和空格的组合(你这里用的是中文单引号,我不知道还有没有其他这种特殊字符,但根据情况补充一下就行了)
中间隔着空白
后面是非字母、数字、下划线的一串内容。
然后把第一组合第二组换个位置(第一组用 $1 表示)
然后发现大家写的正则都不一样,我也学会了新东西~
1 个赞