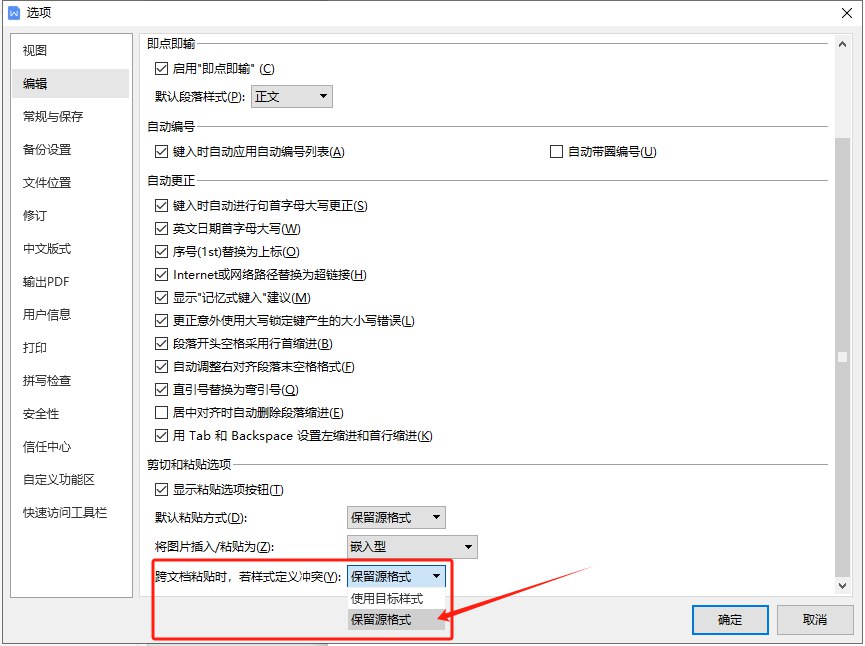
RTRT,
在整理网摘的时候,复制网页上带图片的段落文字,实际剪切板中会生成一个html类型的剪切板,比如这个:
<img src="https://cdn.beekka.com/blogimg/asset/202409/bg2024092303.webp" alt=""
title="" style="margin: 0px; padding: 0px; list-style-type: none;
text-align: left; text-decoration: none; font-weight: normal; font-style:
normal; border: 0.3em solid rgb(224, 223, 204); color: rgb(17, 17, 17);
border-radius: 1em;">
我写了一个python程序,将图片转换为base64嵌入html中:
import win32clipboard
import win32con
from PIL import Image
import io
import re
import base64
import requests
from io import BytesIO
class ClipboardManager:
def __enter__(self):
win32clipboard.OpenClipboard()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
win32clipboard.CloseClipboard()
def decode_text(data):
"""使用 chardet 自动检测编码并解码文本"""
import chardet
try:
detected = chardet.detect(data)
encoding = detected['encoding']
print(f"Detected encoding: {encoding}") # 输出检测到的编码
return data.decode(encoding)
except Exception as e:
print(f"Failed to decode text: {e}")
return data.decode('utf-8', errors='replace')
def extract_image_urls_from_html(html_data):
"""从 HTML 数据中提取图片链接"""
image_urls = re.findall(r'<img[^>]+src="([^">]+)"', html_data)
return image_urls
def download_image_as_base64(image_url):
"""下载图片并将其转换为 base64 编码,并根据图片格式生成正确的 MIME 类型"""
try:
response = requests.get(image_url)
if response.status_code == 200:
image_data = BytesIO(response.content)
# 使用 PIL 来识别图片的格式
img = Image.open(image_data)
image_format = img.format.lower() # 获取图像格式并转换为小写
# 重置指针以重新读取图像数据
image_data.seek(0)
# 将图片转换为 Base64
base64_image = base64.b64encode(image_data.read()).decode('utf-8')
# 生成带有正确 MIME 类型的 Base64 数据
return f"data:image/{image_format};base64,{base64_image}"
else:
print(f"Failed to download image: {image_url}")
return None
except Exception as e:
print(f"Error downloading image: {image_url}, error: {e}")
return None
def download_image_from_html(html_data):
"""从 HTML 数据中提取图片链接,并将其替换为 base64 编码的图片"""
# 提取所有的图片链接
image_urls = re.findall(r'<img[^>]+src="([^">]+)"', html_data)
# 遍历找到的图片链接
for image_url in image_urls:
# 下载图片并转换为 Base64
base64_image = download_image_as_base64(image_url)
# 如果下载成功,则替换 HTML 中的图片链接为 Base64 数据
if base64_image:
# 将原来的图片 URL 替换为 base64 编码的图片数据
html_data = html_data.replace(image_url, base64_image)
return html_data
def get_clipboard_format_name(fmt):
"""获取剪切板自定义格式的名称"""
try:
name = win32clipboard.GetClipboardFormatName(fmt)
return name
except:
return None
def list_clipboard_formats():
"""列出当前剪切板中的所有格式"""
formats = []
fmt = win32clipboard.EnumClipboardFormats(0)
while fmt:
formats.append(fmt)
fmt = win32clipboard.EnumClipboardFormats(fmt)
return formats
def read_clipboard():
clipboard_content = {}
with ClipboardManager():
# 处理 CF_TEXT 格式
if win32clipboard.IsClipboardFormatAvailable(win32con.CF_TEXT):
text = win32clipboard.GetClipboardData(win32con.CF_TEXT)
clipboard_content['CF_TEXT'] = decode_text(text)
# 处理 CF_UNICODETEXT 格式
if win32clipboard.IsClipboardFormatAvailable(win32con.CF_UNICODETEXT):
unicode_text = win32clipboard.GetClipboardData(win32con.CF_UNICODETEXT)
clipboard_content['CF_UNICODETEXT'] = unicode_text
# 处理 CF_BITMAP 格式
if win32clipboard.IsClipboardFormatAvailable(win32con.CF_BITMAP):
bitmap_handle = win32clipboard.GetClipboardData(win32con.CF_BITMAP)
clipboard_content['CF_BITMAP'] = f"Bitmap handle: {bitmap_handle}"
# 注册并获取 HTML 格式的编号
cf_html = win32clipboard.RegisterClipboardFormat("HTML Format")
# 检查并读取 HTML 内容
if win32clipboard.IsClipboardFormatAvailable(cf_html):
html = win32clipboard.GetClipboardData(cf_html)
html_text = html.decode('utf-8')
pprint.pprint(html_text)
clipboard_content['HTML'] = html_text
# 下载并替换 HTML 中的图片链接为 Base64
modified_html = download_image_from_html(html_text)
clipboard_content['HTML'] = modified_html
win32clipboard.SetClipboardData(cf_html, modified_html.encode('utf-8'))
# 处理 CF_DIB 图像格式
if win32clipboard.IsClipboardFormatAvailable(win32con.CF_DIB):
image_data = win32clipboard.GetClipboardData(win32con.CF_DIB)
# 将 DIB 数据转换为 PIL 图像
image = Image.open(io.BytesIO(image_data))
clipboard_content['IMAGE'] = image
# 处理 CF_HDROP 文件路径
if win32clipboard.IsClipboardFormatAvailable(win32con.CF_HDROP):
file_paths = win32clipboard.GetClipboardData(win32con.CF_HDROP)
clipboard_content['FILES'] = list(file_paths)
# 枚举并读取所有其他剪切板格式
formats = list_clipboard_formats()
for fmt in formats:
# 跳过已处理的常见格式
if fmt in (
win32con.CF_TEXT, win32con.CF_UNICODETEXT, win32con.CF_BITMAP, cf_html, win32con.CF_DIB, win32con.CF_HDROP):
continue
# 尝试获取自定义格式名称
format_name = get_clipboard_format_name(fmt) or f"Custom Format {fmt}"
# 获取格式内容
try:
data = win32clipboard.GetClipboardData(fmt)
clipboard_content[format_name] = str(data)[:100] # 截取前100字符避免太长
except Exception as e:
clipboard_content[format_name] = f"Error reading format {fmt}: {e}"
return clipboard_content
# 调用函数并打印剪切板内容
import pprint
clipboard_data = read_clipboard()
pprint.pprint(clipboard_data)
print(clipboard_data['HTML'])
但是实际上粘贴进word中是白色的方块,并不是图片。
尝试复制word中的图片,是这个样子:
<v:imagedata src="file:///C:/Users/ljq29/AppData/Local/Temp/msohtmlclip1/01/clip_image001.png"\r\n
o:title="图形用户界面, 文本, 应用程序 描述已自动生成"/>\r\n
想了解有没有办法或者现成的软件,可以使得我复制的图片自动下载到剪切板(甚至会采用代理帮我自动翻墙下载)?
或者有什么浏览器复制的内容自带图片而不是图片链接?