产品网址:
工具简介:
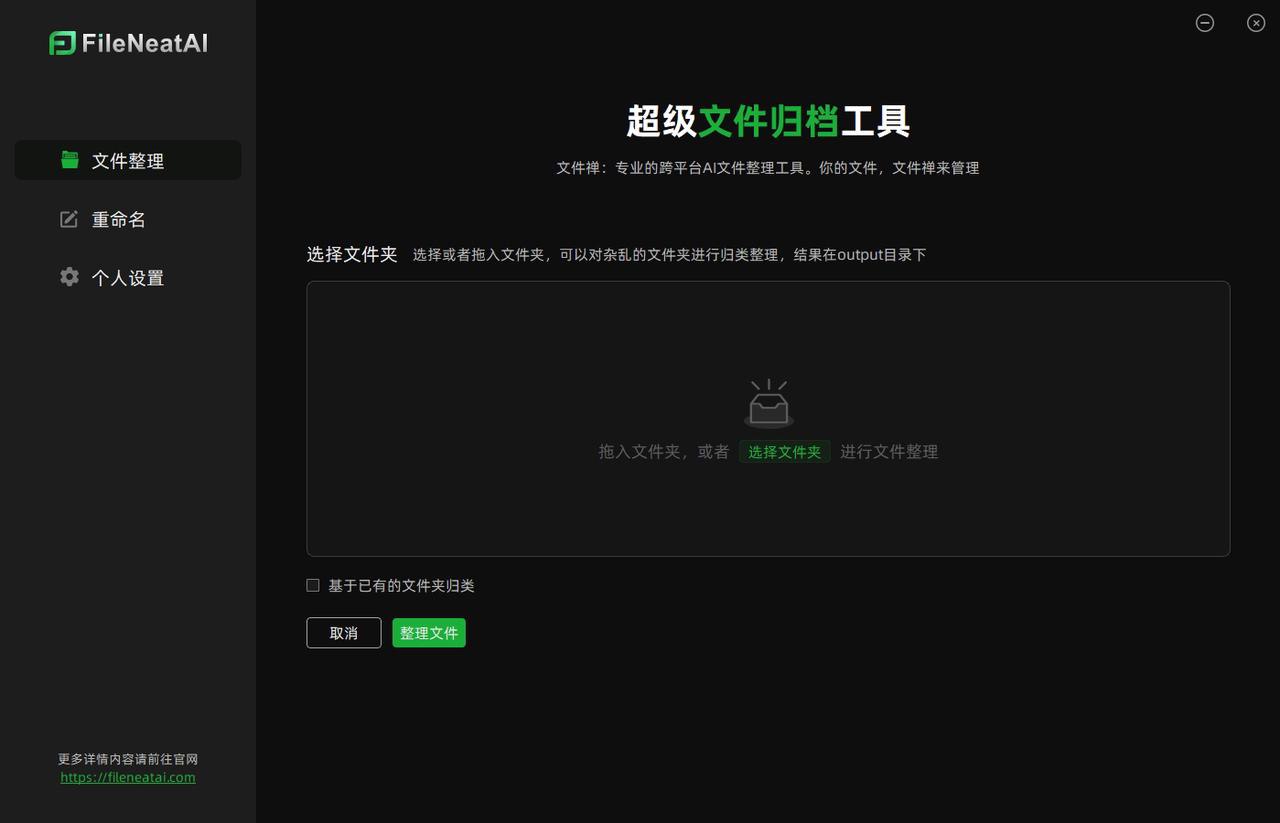
在日常的工作和生活中,我们常常会面对电脑中不断积累的杂乱文件,这种混乱往往让人感到焦头烂额。每次偶然想起来整理时,却总是发现这项任务既耗时又费力。为了解决这一痛点,我开发了一款可以自动化整理和分类杂乱文件的AI工具——FileNeatAI,它可以根据文件夹里的文件内容,通过AI自动的将文件进行分类并整理到不同的文件夹中,同时还可以对一些命名不规则的文件进行智能命名,帮助用户轻松、高效地管理文件,提升工作效率。
如何使用:
- 自动分类杂乱文件 我们日常处理的文件夹中,常常充满了各种各样、不相关的文件,手动整理非常繁琐。FileNeatAI可以自动帮你分类整理这些文件,同时还支持图片文件。使用时,只需将目标文件夹拖入工具界面,点击“整理文件”按钮,软件会根据文件内容智能分析,将属于同一类别的文件归类到相应的文件夹中。整理过程的进度条显示完成后,会生成一个新的
output文件夹,里面就是分类好的文件夹。打开每个文件夹,就能轻松查看分类后的文件。
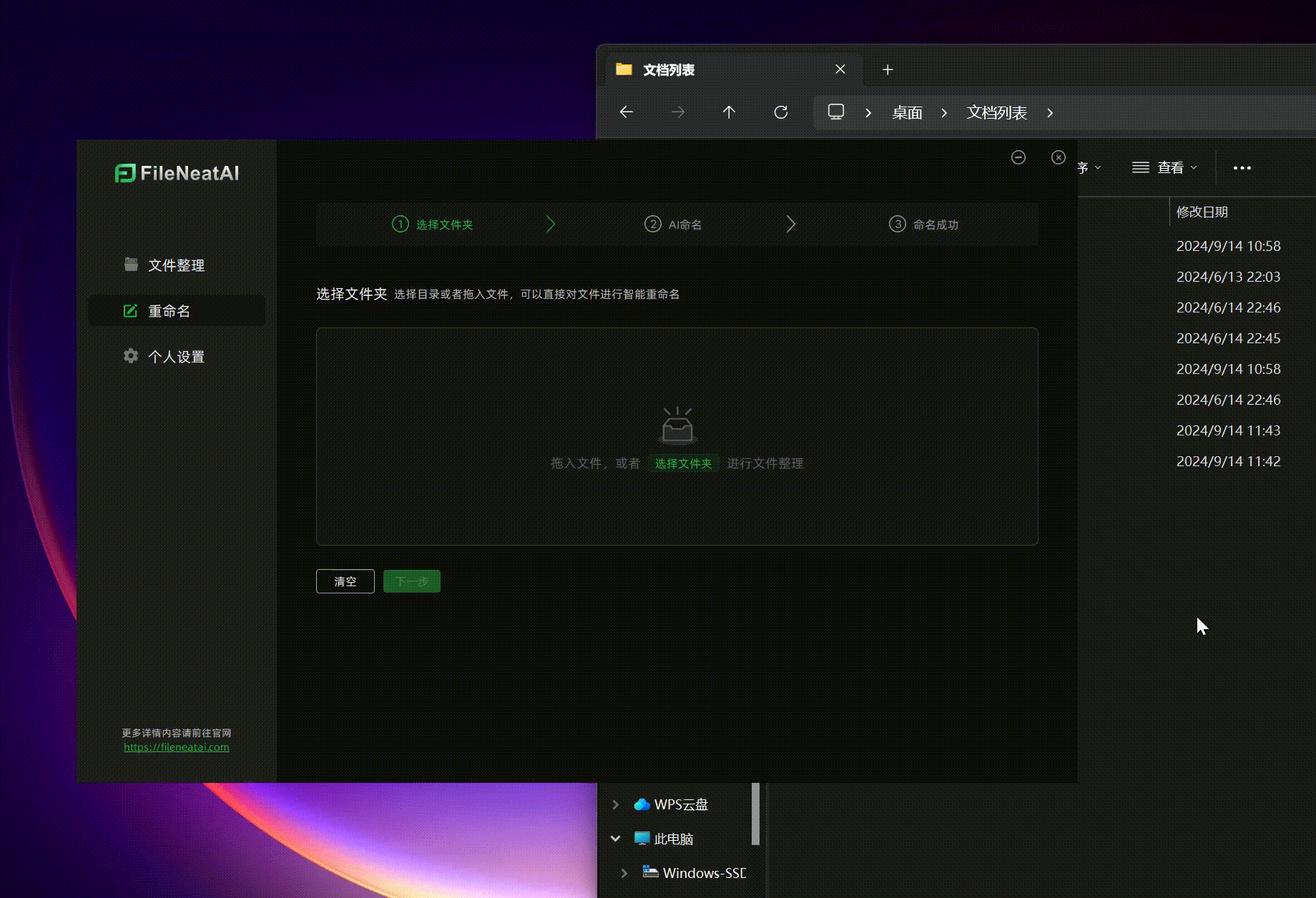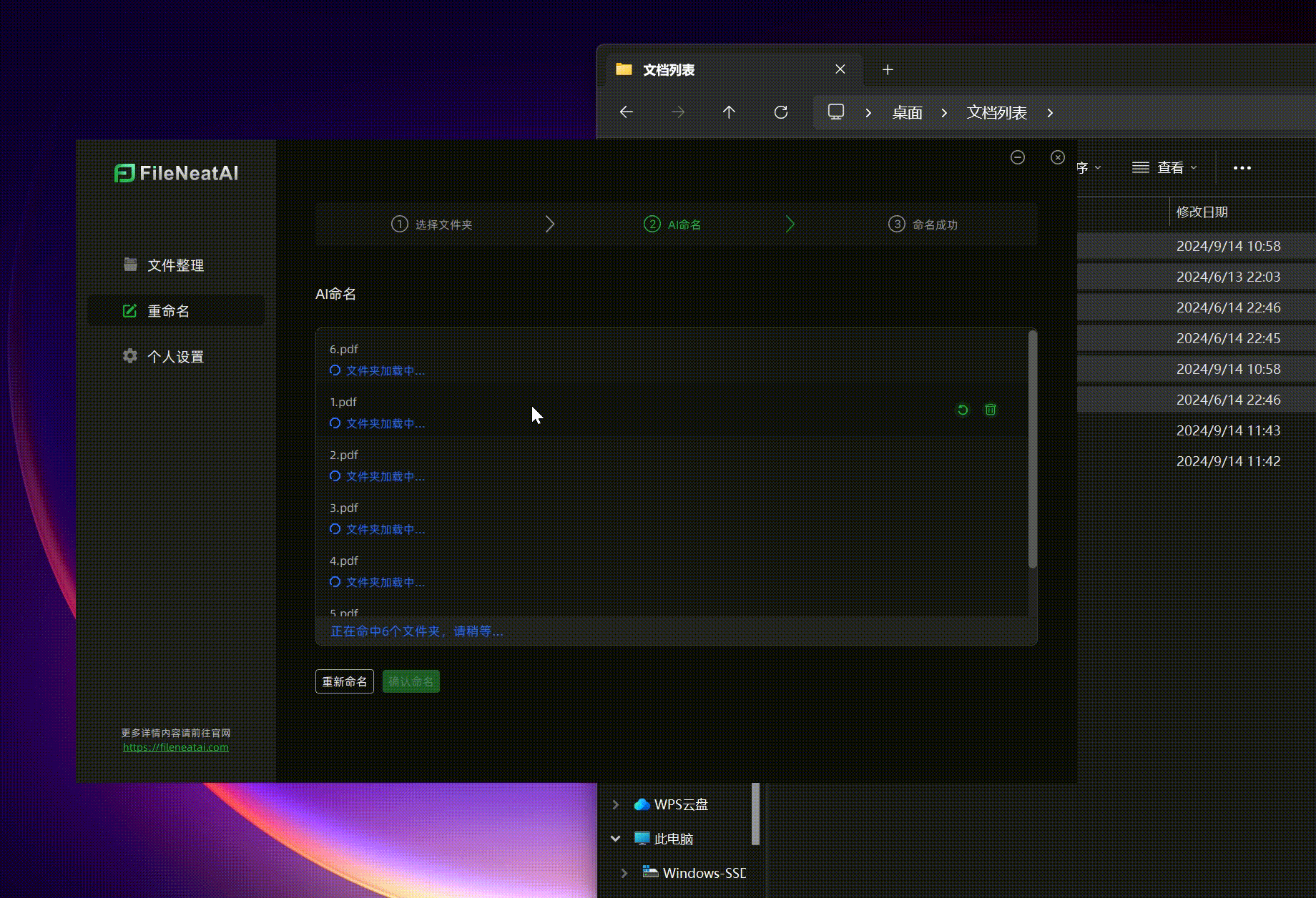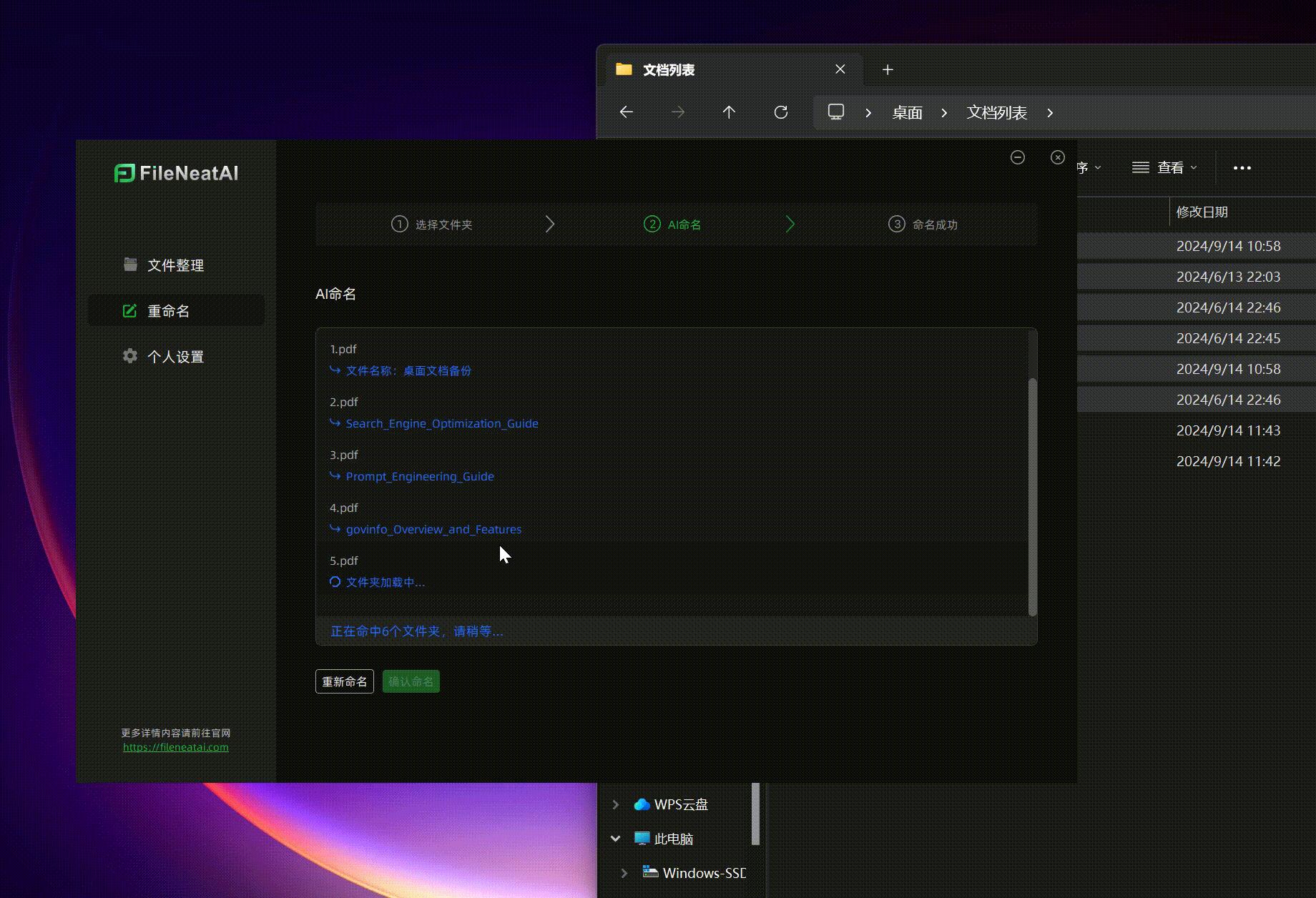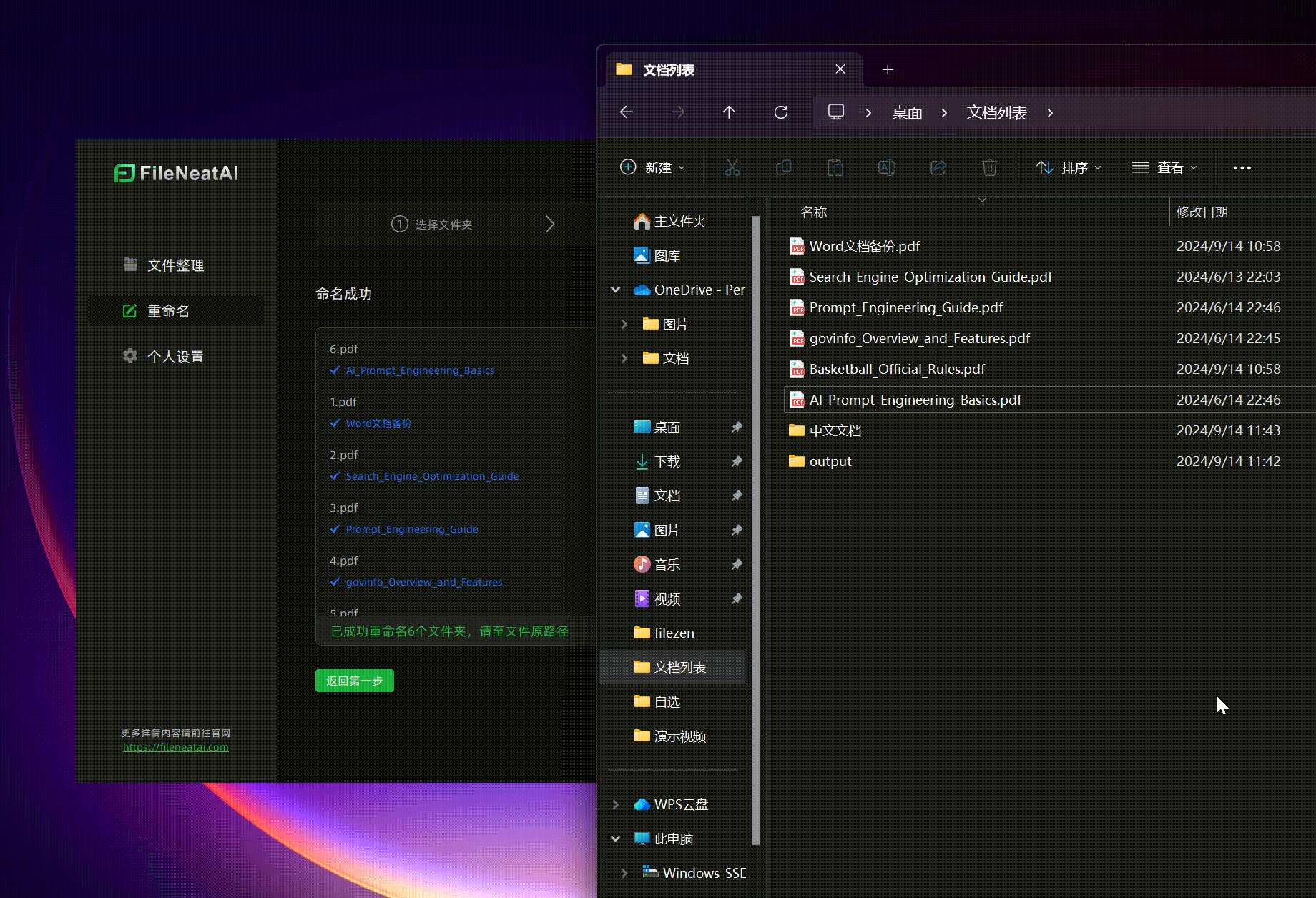
- 批量重命名文件 有时候,我们希望将一些杂乱的文件重命名为更规则、易于记忆的名称,但逐一手动重命名非常耗时。这时,FileNeatAI的批量重命名功能就能大显身手。只需将需要重命名的文件拖入工具,点击下一步,AI会自动为文件生成新名称。如果对默认名称不满意,可以点击右侧的“重试”按钮获取新的命名建议。最终点击“确认命名”,文件便会自动完成重命名,过程简便高效。
- 使用本地模型
软件默认使用在线模型,同时也支持本地模型,可以在个人设置里自行设置。
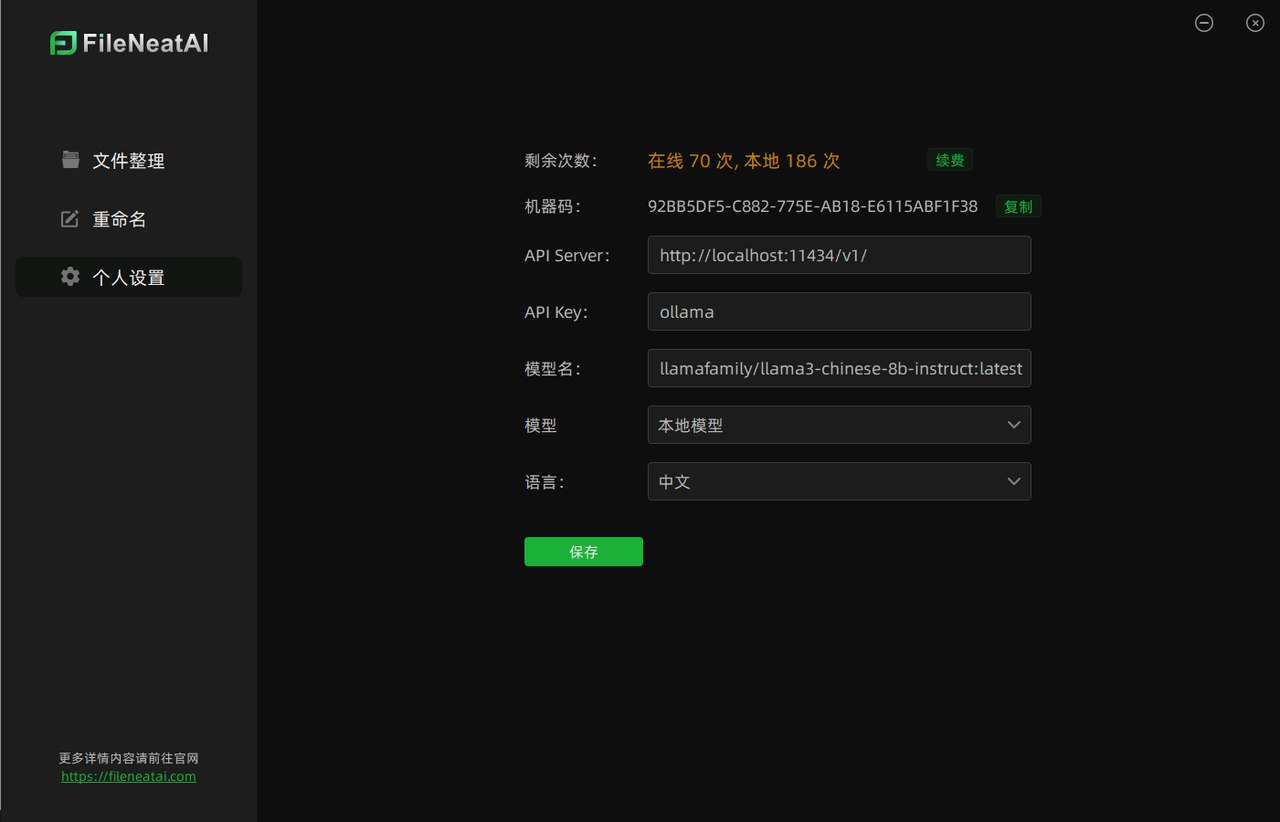
默认是使用在线AI来读取文件,经过很多人的建议,本地文件的隐私防泄漏是一个比较大的痛点,所以本次更新支持本地模型,而且更重要的是选择本地模型的话,将不限制整理的文件数量!个人推荐ollama3,我测试的时候用的这个,效果还行,如果是中文用户的话,推荐模型是llamafamily/llama3-chinese-8b-instruct:latest, 你也可以使用其他国产的大模型都可以,在网站library 这个上面搜索即可。
如何使用本地模型?:
在网站https://ollama.com/ 上下载好客户端后
打开cmd,输入命令
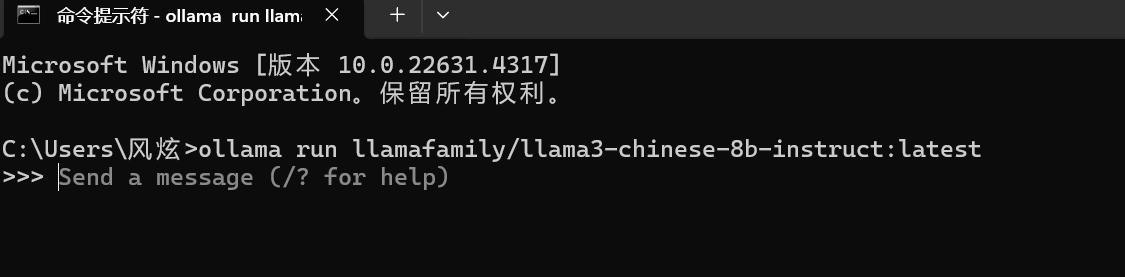
ollama run llamafamily/llama3-chinese-8b-instruct:latest
如果是第一次使用,则会自动下载这个模型,但下载好之后,会变成下面的状态,就表示可以使用了
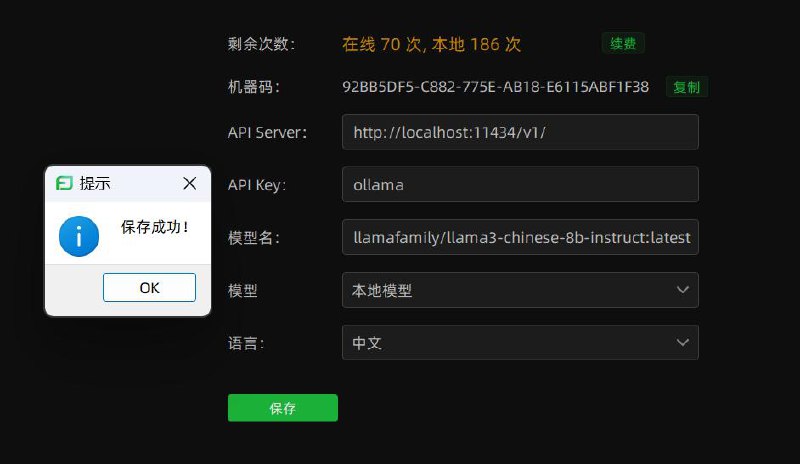
但选择本地模型时候,软件需要几项配置,这里如果不是开发者的话请直接使用我下面的配置:
-
API Server 填写 http://localhost:11434/v1/
-
API Key 填写
ollama -
模型名填写:
llamafamily/llama3-chinese-8b-instruct:latest -
模型 选择:本地模型
填写完成之后点击保存即可使用。
适用人群:
FileNeatAI适合广大学生、上班族、白领、文职人员及任何需要使用计算机办公的用户。无论是日常工作还是学习中频繁处理文件的场景,FileNeatAI都能为你提供简便快捷的解决方案
产品价格:
FileNeatAI采用按使用次数收费的模式,灵活满足不同用户的需求。具体价格如下:
-
10元:线上模型使用20次,本地模型使用100次
-
50元:线上模型使用100次,本地模型使用1000次
-
100元:线上模型使用300次,本地模型使用99999次