有同学问:
想找一个win平台,将文字选取复制到剪切板后自动统计字数并显示的工具,最近文字工作比较多。
有同学问:
想找一个win平台,将文字选取复制到剪切板后自动统计字数并显示的工具,最近文字工作比较多。
星河下电子荒原 同学提供了一个方案:
dragKing
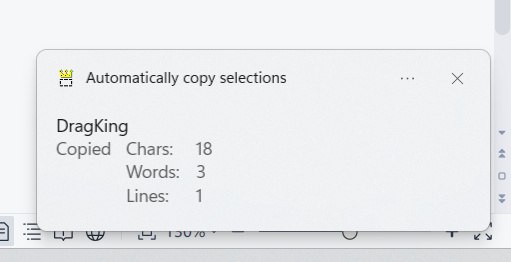
假设没有这种软件,我们可能需要写一个出来
大多语言都能实现读取和监控剪贴板内容,这不是啥大问题,我认为主要问题有两个
1,UI设计:要让统计的字数以何种方式,在何处出现。弹窗提醒我认为不是一个好选择,用户只能查看一次;置顶一个小窗口来显示又太占用屏幕空间了。
2,用户设置:设置选项应该如何排布,使得其能够应对用户对中英文统计、无标点统计、无符号统计的不同需求
中文字数怎么计算,emoji 字数怎么计算……反正吧,挺复杂的其实
统计字数还蛮麻烦的,之前写过一个偷摸写小说的软件(就是只有一行、没有操作栏、背景可选颜色之类的),想加一个字数统计
就发现我的软件、word、Obsidian和某小说平台的字数都是不一样的,甚至一开始差距还蛮大的,调整了好几次才缩小了差距
以前搞过一个油猴脚本来统计字数:
https://greasyfork.org/scripts/10763
CopyQ 支持脚本.
其中有个API 是 Length. 可以统计字符串长度.
如果只是要长度信息, 不考虑剪贴板增强.
可以用AHK ,但是意义不大.
大概的代码如下, 没有优化, 所以如果2次复制的长度一样会不提示. 但是明白这点也不算bug.
#Persistent
SetTimer, testmt, 10
testmt:
a :=StrLen(clipboard)
sleep,100
b :=StrLen(clipboard)
;每一百毫秒,剪贴板送到a和b变量空间,
if(a<>b)
{
Msgbox %b%
}
return
```
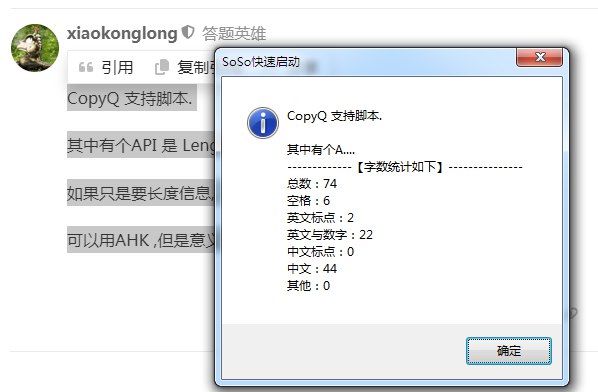
SoSo快速启动 刚好弄了一个 不知这样适不适合
https://wwgz.lanzouw.com/b00mouxvyb
密码:hpjc
搓了一个,看看能不能用
欢迎任何建议和批评!后续有需要会依照需求更新软件
歪个楼,有个 Linux 系统上的解决方案:命令行执行如下命令
watch -p 1 "xsel -ob | wc -m"
其中,
watch -p 1 代表每 1 秒运行一次后面引号中的命令,并输出运行结果xsel -ob 用于将剪切板中的内容输出到终端中wc -m 用于计算文本的字符数(但需注意,汉字、英文字母、阿拉伯数字、换行符都会算一个字符)其实到最后,还是楼上的那个问题:以什么规则进行字数统计?
我的解决方案是统一使用或者转换为unicode编码,根据码区定位
参见部分我的解决方案实现
// 每组大括号代表一个取值范围,例如0x20~0x2f
// 符合下列范围的取值均为英文字母标点
// 注解:定义能够在unicode官网找到
std::map<int, int> EnglishPunctuationRanges = {
{0x20, 0x2F},
{0x3A, 0x40},
{0x5B, 0x60},
{0x7B, 0x7E}
};
// 检查某字符在何取值范围内
bool CheckChar(std::map<int, int> ranges,int c)
{
for (const auto& range : ranges)
if (c >= range.first && c <= range.second)
return true;
return false;
}
我感觉三楼说的可能还有一层意思:涉及到像论文、报告、作文这种有字数要求的文书时,要用什么样的字数计数规则?比如,标点符号算不算字数?英文单词算几个字?阿拉伯数字算几个字?
ahk 写个脚本
我写个伪代码:
快捷键:ctrl + alt + c
功能:读取剪切板,弹窗提示当前剪切板内容 + 当前剪切板字数
; 定义快捷键 Ctrl + Alt + C
^!c::
; 读取剪切板内容
ClipboardContent := Clipboard
; 计算剪切板内容的字数
Length := StrLen(ClipboardContent)
; 显示消息框,包含剪切板内容和字数
MsgBox, 剪切板内容: `%ClipboardContent%`%n字数: %Length%
return
能区分统计中英文不
十分有价值的建议!我认为它可以作为一个可以选择性启用的功能加入我的解决方案
如果使用ahk,最快的办法应该是使用RegExReplace函数替换所有[表示单个中文字符的正则表达式],得到的计数即为中文字数总数,英文同理。
需要考虑的只是
1.如何使用正则表达式表示单个中文字符
关于这个问题,可能还是要依靠unicode码区定义,通过匹配字符的unicode值来确认是否为中文
2.性能问题
我没有使用过ahk,所以没有任何优化意见。但是因为它是基于脚本解释器的语言,所以我不知道面对大段文本时它的性能表现如何
另外,您的提问给了我新灵感!
我发现自然语言中汉字、英文字母总是成段出现,很少出现每一个汉字都紧跟着一个英文字母的情况。
由上可得,我们可以在汉字检查时标记出所有汉字段落,在英文字母检查时跳过这些已检查的段落,能够规避大量无意义的检查。这样处理大量文本时性能就会提高
这个英语应该是按照 字母算的长度。。。 空格也算
有道理的!应该允许用户可选地排除某些字符