用一个例子描述问题
现在我使用Ditto快速复制两组元数据的信息,使用Ditto全体粘贴,得到:
(举的例子是三项,但是实际使用时经常10项以上)
可乐
20
格瓦斯
35
咖啡豆
54
现在想把奇数行和偶数行分离
已知办法:Excel
目前我知道的办法是使用Excel
使用公式:
=OFFSET($C$1,(ROW(A1)-1)*2,0)
=OFFSET($C$1,ROW(A1)*2-1,0)
可以分离出来
有没有其他思路?
我觉得这个小流程还挺常用的,尤其是在使用Ditto整理数据的情况下。
我觉得使用Excel还是有点「重」,但我目前不会编程,所以没有思路了,想问问坛友有没有更快捷的办法
再延伸就是:多组元数据线性排列时,怎么分离?
autohotkey呀,还复制什么,全部自动。
不过在其它平台可能python更好。
dms
(稻米鼠)
3
我一直认为普通用户学一点编程也是极好的,不一定真的写什么程序,但是给自己带来的便利真的是可感知的。
或者退而求其次一些,那么学一些正则表达式也是性价比很高的。
然而……唉,我的教学生意何止门可罗雀,就……嘤嘤嘤
正经回答,讲一下用正则表达式的方法吧,可能容易理解一些。首先把文件备份好,以防万一搞错,现在我们称最初这份文件为原始文件,简称:源文件。
在源文件里搜索 :(.*\n).*\n,解释一下:
. 代表任意字符* 表示前面的字符出现 0 或者多次- 正则表达式默认贪婪匹配,就是说尽可能匹配最长的情况,所以上面两个连起来可以匹配一整行的内容
\n 代表换行- 现在如果忽略小括号,就很容易看出这是匹配了两行内容。
注意,搜索时要开启对正则表达式的支持。
然后小括号表示分组,现在这里只有一个组,就是第一行的内容,我们用 $1 来标识。于是搜索 (.*\n).*\n 并替换为 $1 就实现了每两行的内容替换为这两行中的第一行,结果就是只剩下了奇数行的内容。
偶数行同理,把分组放后面就行了,记得回源文件重新查找替换。
感谢回答,编程我一定会去学的,刚开始接触这类工作,深知编程的便利性。但是现在知道的太少,思路太受限制了
正则表达式打算马上去学一学
kookiao
(llll)
5
excel 有插件的,去下载个 (方方格子) 里边有许多功能,比如隔行选择, 研究下, 你就会了, 刚没多想,
隔行选择是 kutools 里的功能
1113
7
sed '1d; n; d' myfile.txt > even.txt
sed 'n; d' myfile.txt > odd.txt
来自https://www.reddit.com/r/vim/comments/59yabt/select_odd_or_even_lines_for_future_copy/
至于windows怎么用sed命令,装个git就带了,或者用wsl也行。
wdssmq
(沉冰浮水)
8
所以「如果实现」里其实还是要讲清楚希望如何触发。
比如可以把原始文本写入一个 txt 文件里,,拖动文件到另一个文件的图标上执行,然后同目录下自动生成 a.txt 和 b.txt 两个文件;
bat、bash 或者 py 之类的可以实现这种效果;
或者弄个网页,文本框里输入,点击按钮输出。。
类似下边这样:
https://codesandbox.io/s/optimistic-shtern-pldgr?file=/index.html
↑ 上边项目并没有完成,只是告诉你可以用这个在线工具写,代码提示比不上编辑器,但还是蛮不错的。。
写完也有单独的地址访问使用:https://pldgr.csb.app/
下边代码单独在浏览器控制台执行也能看到效果:
(() => {
// 原始文本,实际可以从 HTML 文本框中获取
const text = `
可乐
20
格瓦斯
35
咖啡豆
54
`;
// 按行拆分为数组
const arr = text.split('\n');
// 定义两个空数组
const arr1 = [], arr2 = [];
// 单双行拆分
arr.forEach(function (line, index) {
if (index % 2 === 0) {
arr1.push(line);
} else {
arr2.push(line);
}
});
// 输出结果,同样也可以写入到 HTML 文本框中
console.log(arr1.join('\n'));
console.log(arr2.join('\n'));
})();
allor
(allor)
9
用 excel 不写公式也可以的,第一次粘贴到A2,第二次粘贴到B1,然后排序,再删掉A列内容为数值的行。
一个 AutoHotKey 脚本,先 Ctrl + C 复制内容到剪贴板,之后按 F7 复制奇数行,F8 复制偶数行。
正则用在这个场景其实还有些麻烦,主要问题是需要处理不同的换行类型(LF, CRLF),以及注意最后一行可能没有换行符。正则参数前加 m) 是开启 multiline。
参考: Regex to remove EVEN lines - Stack Overflow
F7::
Var := Clipboard
Odd := RegExReplace(Var, "m)^(.*)\r?\n.*(\r?\n|$)", "$1`n")
SendInput, %Odd%
Return
F8::
Var := Clipboard
Even := RegExReplace(Var,"m)^.*\r?\n(.*)(\r?\n|$)", "$1`n")
SendInput, %Even%
Return
效果
dms
(稻米鼠)
12
只是奇偶倒也还好,但推而广之之后,收益率最高的还是正则,毕竟对于一般复杂的情况,在程序内的处理方法大多也是正则。
以题主给出的示例为例,如果问题改为提取数字行和非数字行呢?
\d 代表一个数字\D 代表一个非数字的字符+ 代表将前面字符重复 1~n 次
查找 \d+\n 替换为空,则删除所有数字行
查找 \D+\n 替换为空,则删除所有非数字行
dog
(荒废千年)
13
不光是奇偶行,我还经常碰着三数位行,四数位行的,一般都是用Excel,不知道有啥通用点的办法
类似
可乐
有毒
20
格瓦斯
没毒
35
咖啡豆
过敏
54
这个,怎么会这样?
如果,只是为了解决一个问题,那抄别人的,或者用现成的都可以。
但是,这种事太多了,每次为了解决一个问题,学习一个,甚至几个工具的参数,将来维护还看得懂吗?要扩展功能呢?
这些自用的脚本第一考虑就应该是语义,写过的函数还可以复用,长远看这样效率才高。
excel不算重吧.
支持脚本的剪贴板工具, 我目前用的有2个.
一个是CopyQ,
另一个是ClipboardFusion
这两个都可以根据个人需求写出针对性的功能, 而且支持自定义快捷键.
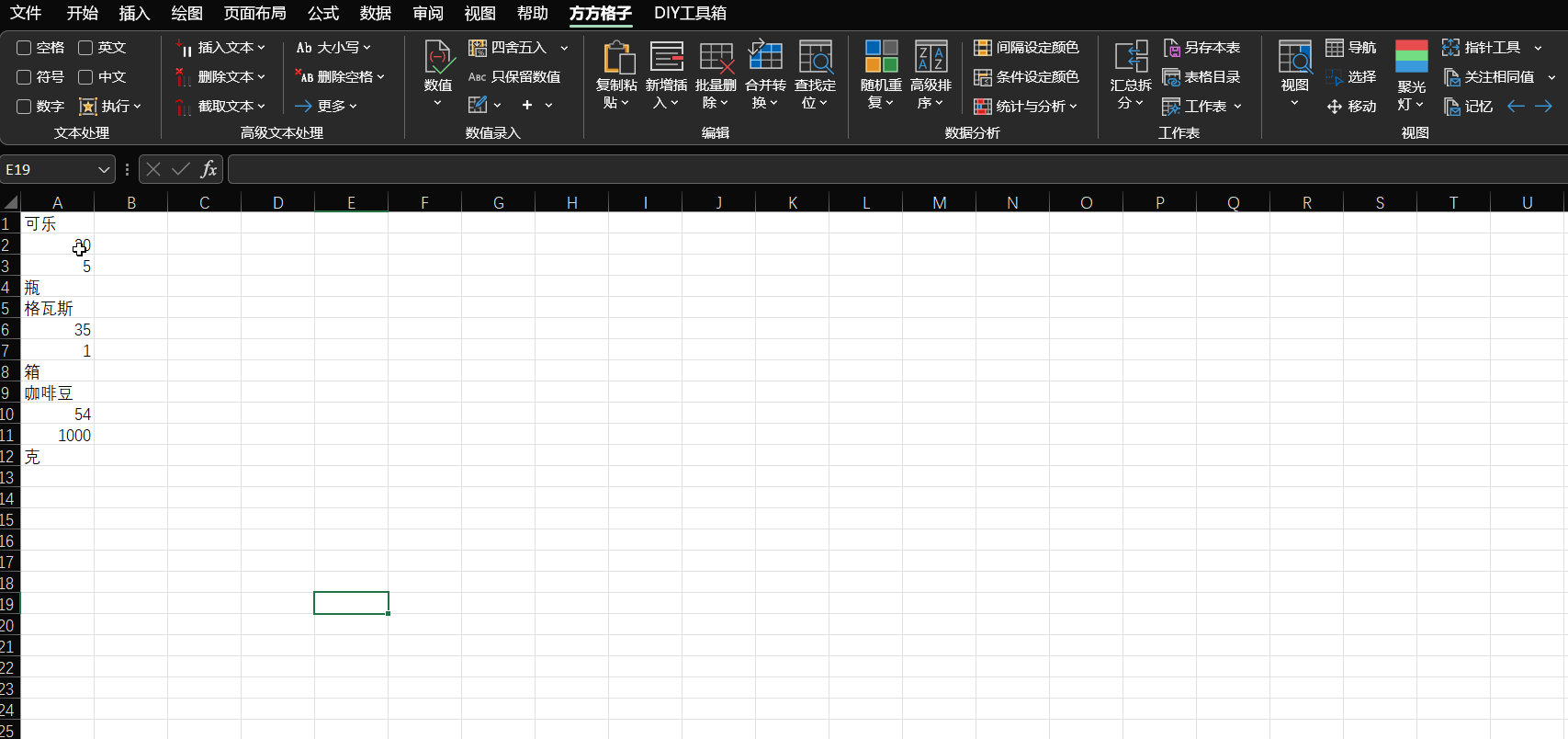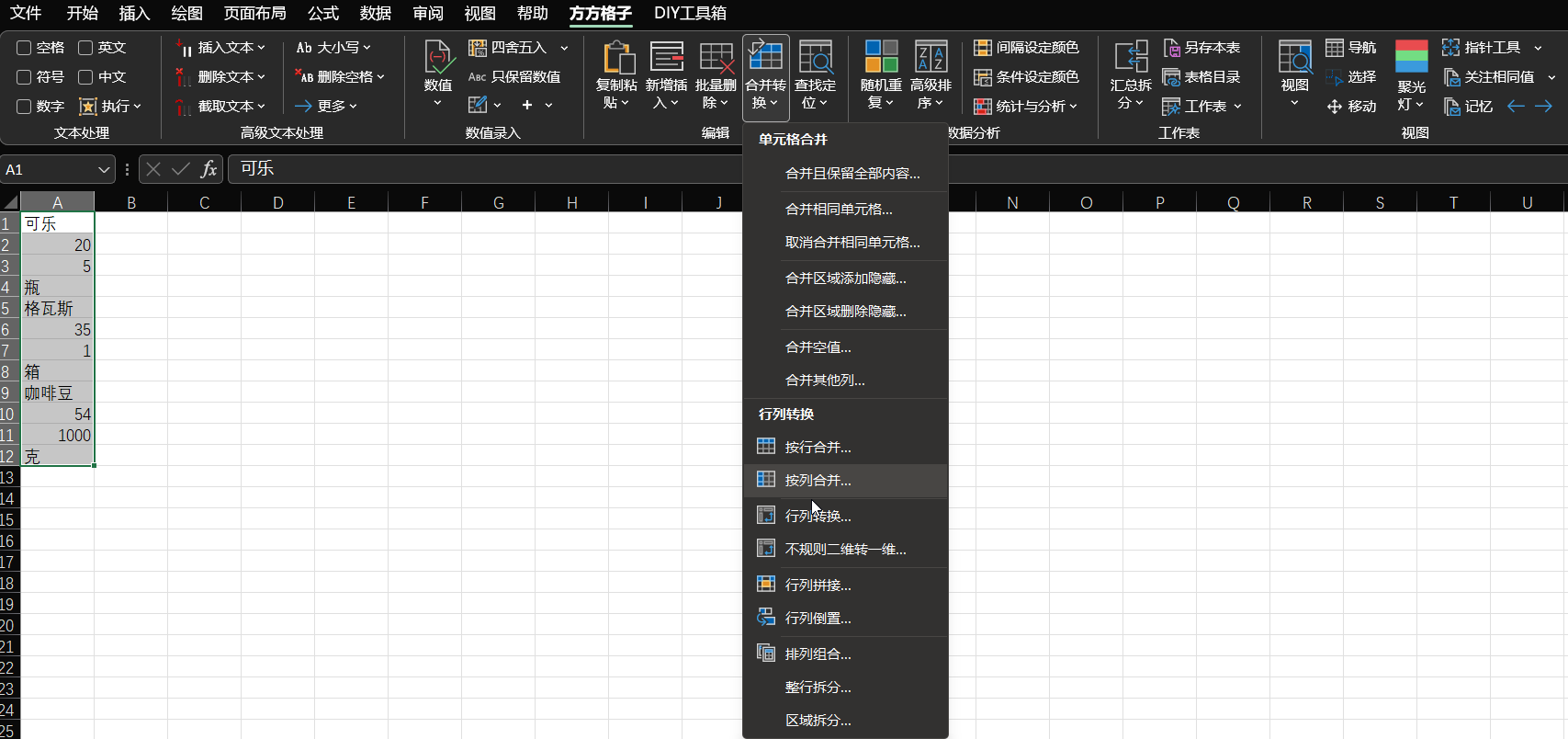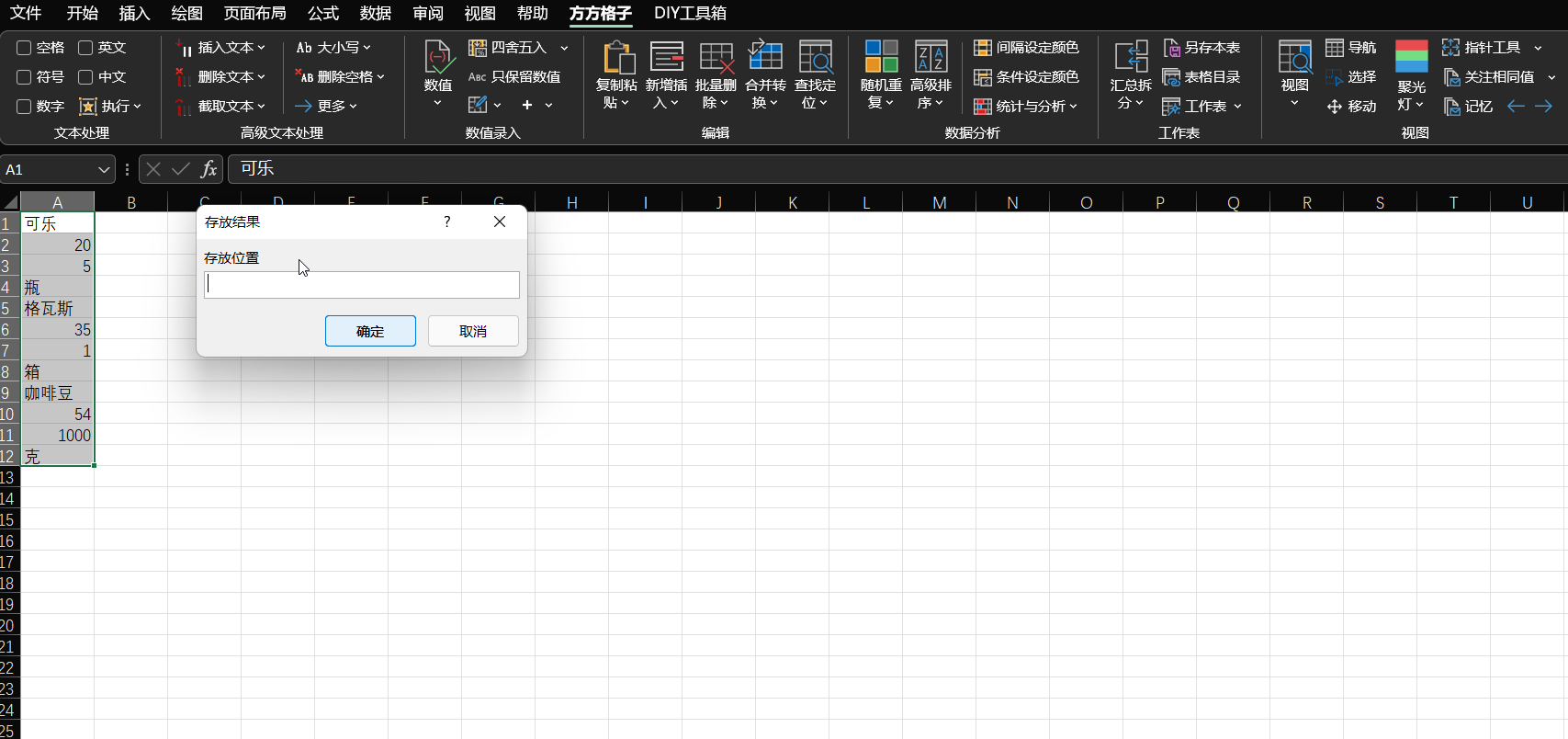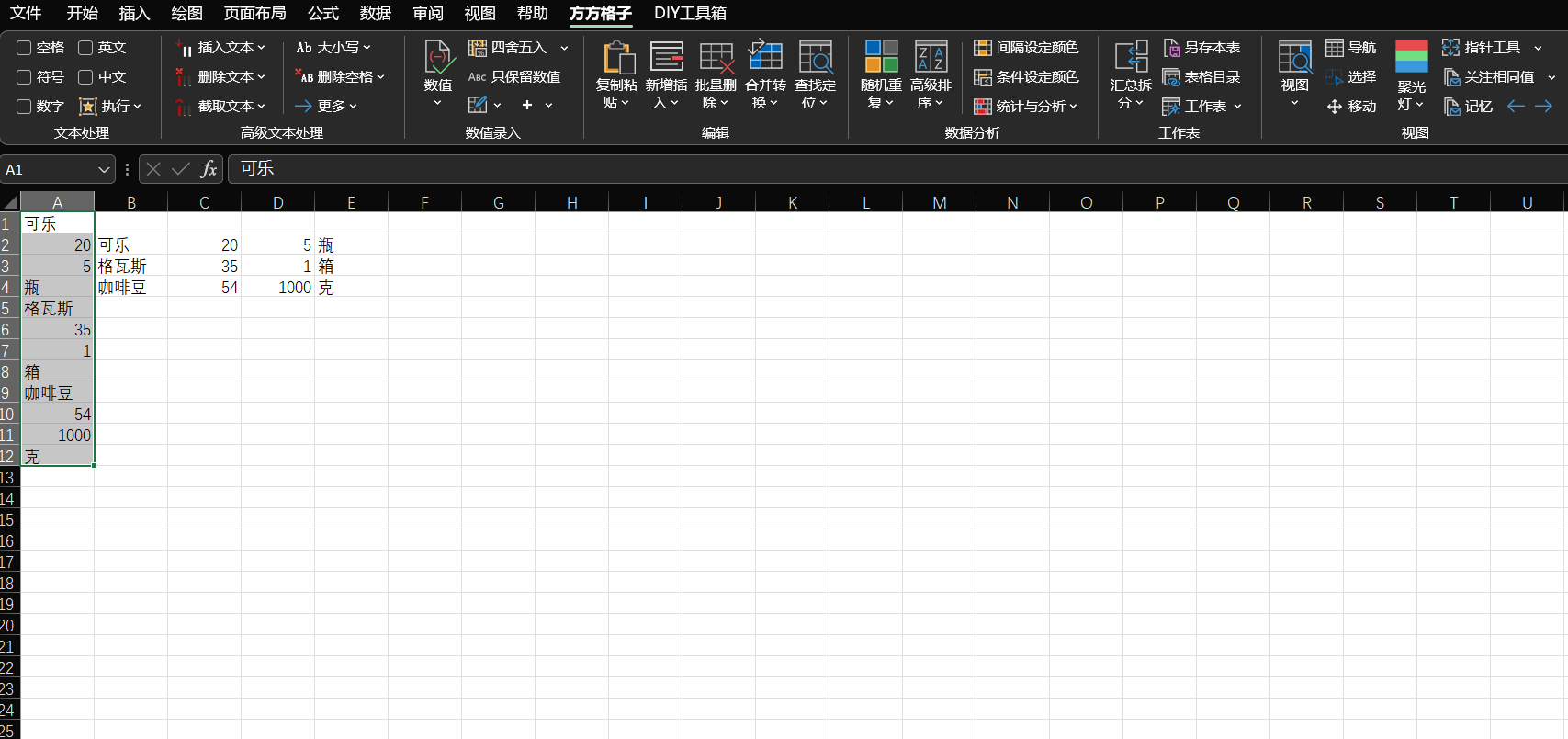
延伸一下,关于多行数据分离的问题。如果用了 kookiao 提到的方方格子插件,则可以简单地直接完成,如下图。
如果手头只有 Excel,不想用外部插件,也不想写公式,有个简单的方式:多加一列,按照每个数据占据的行数给行标号(1, 2, 3…),然后用内置的排序 / 筛选功能,如下图。

另外吐个槽,建议把论坛的图片大小限制调大到 1M,压缩 GIF 到 512K (当前的大小限制)有些困难。
dms
(稻米鼠)
19
参照 11 楼,即可,反正删掉所有非数字行就可以。
如果特征不是数字,而是隔三出一,隔四出一,则参照 3 楼,稍作修改即可。但如果是隔二十出一这种,不断重复写就比较难过了,所以可以这样写:
(.*\n){20}(.*\n)
大括号中的数字表示把前面的组重复 20 次。然后因为我们要的是后面的分组(第二个),所以替换为 $2 即可
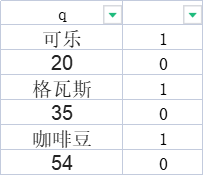
| q |
|
| 可乐 |
1 |
| 20 |
0 |
| 格瓦斯 |
1 |
| 35 |
0 |
| 咖啡豆 |
1 |
| 54 |
0 |
如果只是奇偶行,可以在旁边加辅助列,一行是1,一行是0,筛选数字行就OK了,有excel,不用其他软件或插件