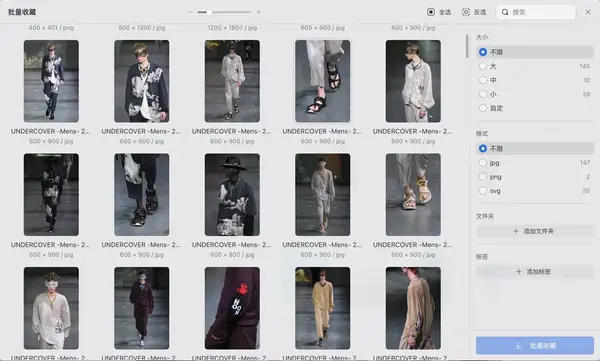
Shruru
(Shurur)
1
但我代码小白,完全不会
网址:https://www.fashionsnap.com/collection/undercover/mens/2025ss
====
我们可以看到文件名是很有规律的:
*00004-aab99df6-a3cf-4368-8fb6-74487152edf7.jpg
*00008-27fad377-7bfe-4159-870f-087b857c00ce.jpg
但为了防止批量下载,在最后加了一串随机字符,这可把我难倒了…
试了 Chrome 的图片批量插件似乎都没办法。通配符不知道怎么写,或者思路不对?
例如:
备注:我是苹果系统 Mac Mini / Chrome 浏览器
如果有办法,请赐教。不胜感激~会发红包

dubc
3
直接把所有jpg都下载下来。然后按照大小和尺寸过滤。
Shruru
(Shurur)
4
能具体点吗?我大概能懂你的意思了,但不会写这个正则表达式。
现在我用的是 Chrome 插件 - 图片批量下载,它界面里只有通配符等,好像没有正则…
kimi360
(KIMI)
5
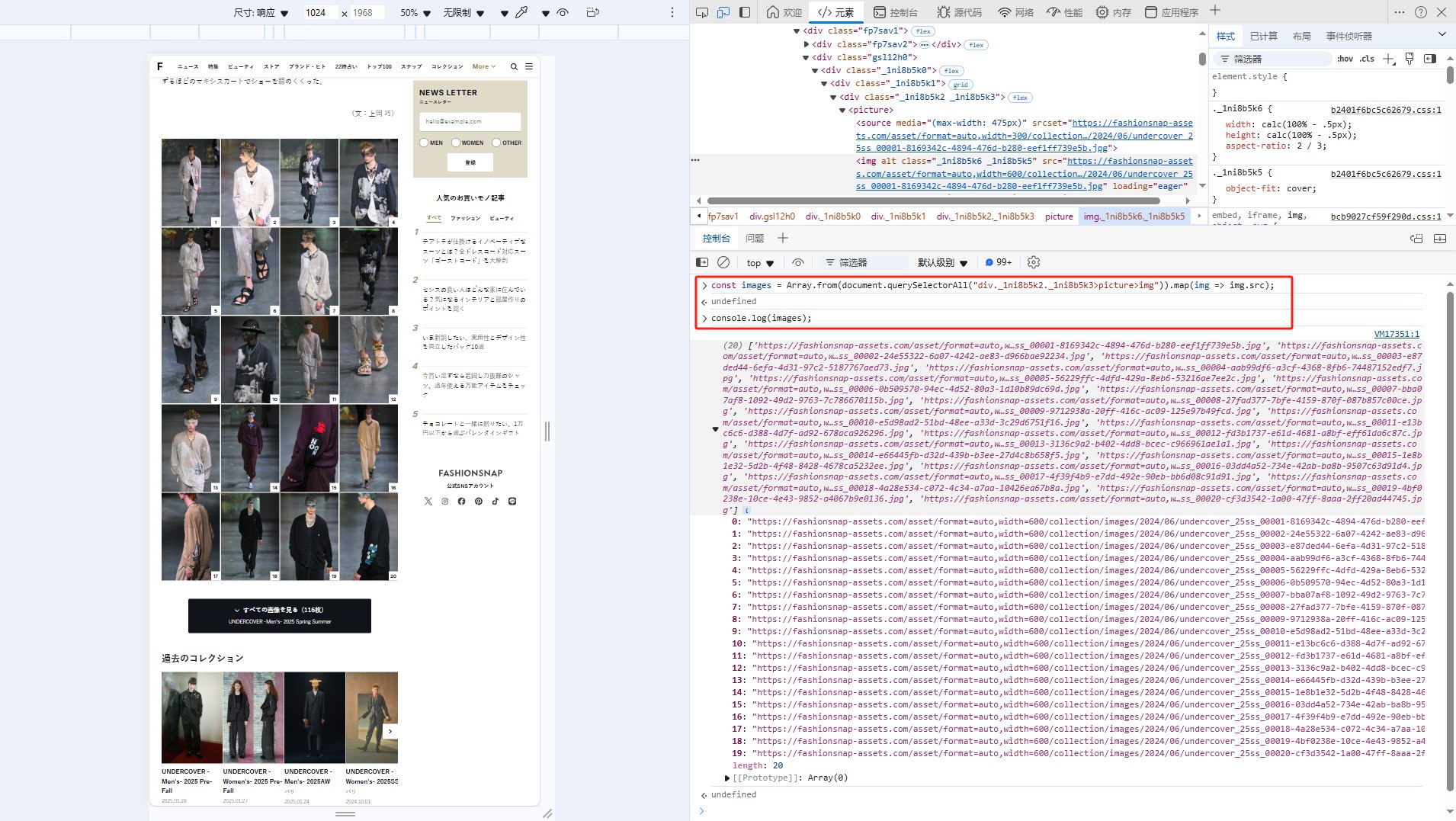
在 Chrome 控制台(F12 → Console)中执行以下代码:
const images = Array.from(document.querySelectorAll("div._1ni8b5k2._1ni8b5k3>picture>img")).map(img => img.src);
console.log(images);
打开了看了一下,图片都放在 img 标签里面的,如果用Python就很简单了
<img class="_1g6werdg" src="https://fashionsnap-assets.com/asset/format=auto,width=800/collection/images/2024/06/undercover_25ss_00001-6a922509-1dcc-48d1-b77e-c144d1d32668.jpg" alt="UNDERCOVER 2025年春夏">
额外使用 request、BeautifulSoup 两个库很容易实现:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 目标URL
url = "https://www.fashionsnap.com/collection/undercover/mens/2025ss/"
# 创建一个文件夹来保存图片
save_folder = "undercover_images"
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 发送HTTP请求
response = requests.get(url)
# 解析页面内容
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")
# 下载图片
for img in img_tags:
img_url = img.get("src")
if not img_url:
continue
img_url = urljoin(url, img_url)
img_data = requests.get(img_url).content
img_name = os.path.join(save_folder, img_url.split("/")[-1])
with open(img_name, "wb") as f:
f.write(img_data)
print(f"图片已下载: {img_name}")
这个代码没有使用多线程,能跑就行。
我也是代码小白,使用现成工具 Eagle 貌似效果也还不错
shadows
(shadows)
8
chrome插件有批量下载图片的,可以按照图片宽/高过滤…记不起名字了
tjsky
(去年夏天)
9
图片助手(ImageAssistant) 批量图片下载器

没啥问题,扩展直接抓的到。
页面右键-图片助手-提取本页图片
1113
10
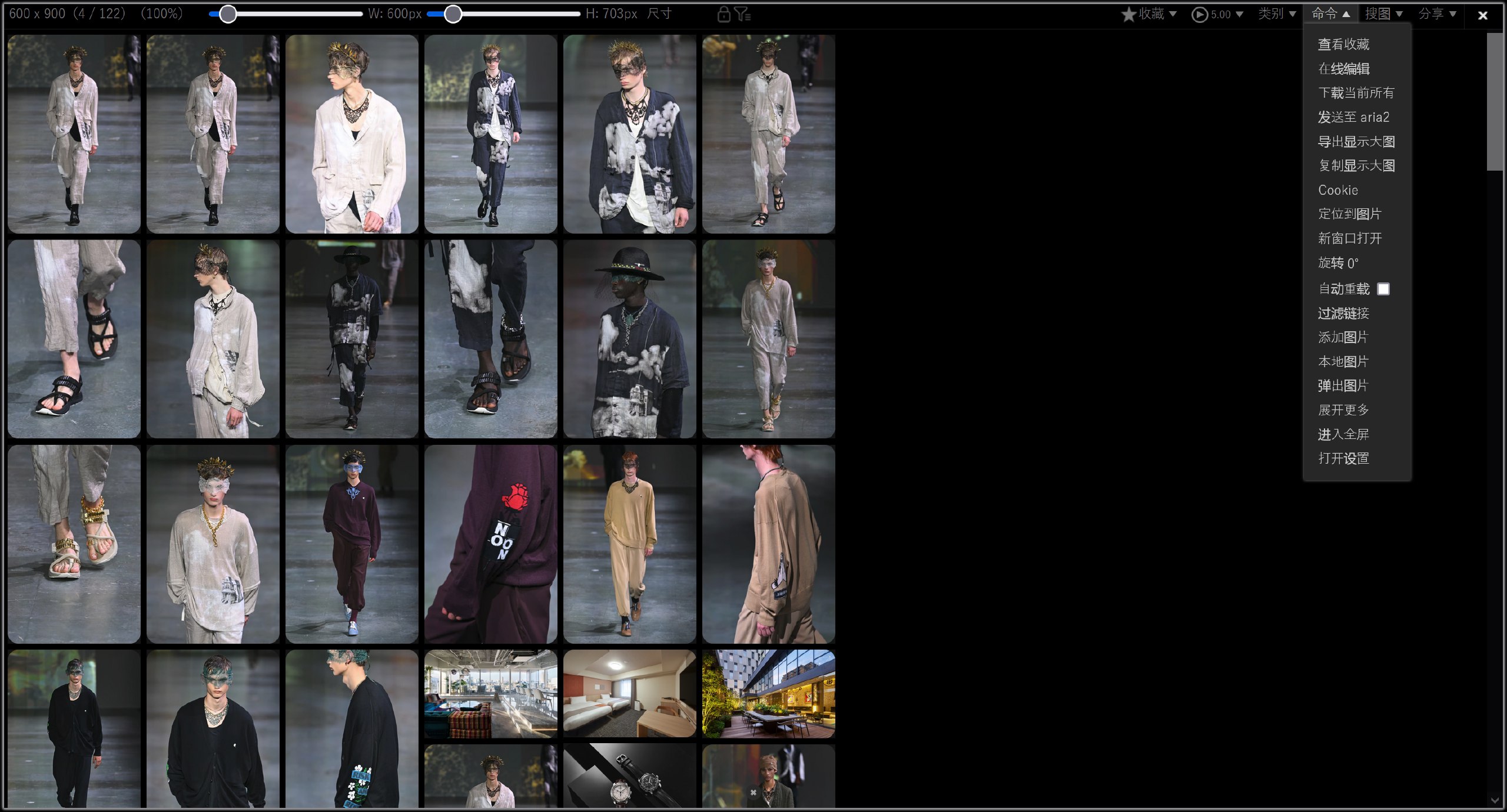
浏览器上的图片需求基本都可以用Picviewer CE+搞定
Shruru
(Shurur)
15
我原本就是这个插件,是可以抓到。但发现,它连其他页面的图片也抓取了。而不是仅仅当前本页的。
tjsky
(去年夏天)
17
选择【抓取当前页】的话,设计上是只抓取当前页面上的图片的。
我估计可能是因为网页上有些元素虽然看不到,但是网页源码里图片的地址已经被写上去了。
Shruru
(Shurur)
18
这个也不行的。抓取的是当前页面的缩率图。并不是大图(原图)。原图是点进去每个的。
Shruru
(Shurur)
19
Eagle也是抓取的是缩率图 600x900 分辨率的,原始的图片是有 2000.
Shruru
(Shurur)
20
经过几天,谢谢大家的回复。但其实都是不对的思路 - 网站图库是有缩率图的(小图),大多数的方案都是根据当前页面来批量下载,其实下载下来的都是缩率小图,大图是要经过点击小图才会显示大图(进入缓存的)。所以我还是觉得应该从 文件名来判断直接拉出列表,然后下载。但每个大图文件名都加了随机数如第一帖上说的那样。。。
换我的话直接妥协使用半自动方法了:
半自动主要是翻页,每次触发都是翻页+获取图片信息(或直接下载)
以下搭配自动化工具,如 Keyboard Maestro
笨法
翻页用 ←→
给 Option + 右键绑快捷键,下载用这个快捷键
再高级一点
翻页用 ←→
运行 JavaScript 提取图片链接到一个文件中
使用正则表达把尺寸正确的链接提取出来(链接中包含了尺寸信息)
然后再批量下载。
正则表达和 JavaScript 可以直接问 AI。
let images = document.querySelectorAll('img');
images.forEach(img => console.log(img.src));