对换表类似
1111=aaaa
2222=bbbb
3333=cccc
或其他相近格式的txt,或干脆就是个 excel 表
然后直接调用这个表进行文本文件批量替换的软件
对换表类似
1111=aaaa
2222=bbbb
3333=cccc
或其他相近格式的txt,或干脆就是个 excel 表
然后直接调用这个表进行文本文件批量替换的软件
可以借助 busybox-w32 + sed + awk 来完成。
为了表述方便,本文作如下约定:
replace.sh是脚本文件list.csv是文字对换表
处理单个文件,可用这个脚本:
#!/bin/sh
FILE=$1
L=1
E=`awk 'END {print NR}' list.csv`
while [ $L -le $E ]
do
A="`awk -F ',' -v L=$L 'NR==L {print $1}' list.csv`"
B="`awk -F ',' -v L=$L 'NR==L {print $2}' list.csv`"
sed -i "s/$A/$B/g" "$FILE"
unix2dos "$FILE"
L=$(($L+1))
done
将上述内容保存为脚本文件 replace.sh。
对换表保存在 list.csv 文档中,第一列为原始文本,第二列为替换文本。比如:
111,AAA
222,BBB
假设原始文本内容为 “测试内容111和测试内容222.”,替换后为 “测试内容AAA和测试内容BBB.”。
然后,下载 busybox-w32,将 busybox.exe 复制到 X:\Windows\ (X 为系统盘盘符) 目录下,在CMD中执行如下命令启动脚本:
busybox ash ./replace.sh ./1.txt
其中,1.txt 是要处理的文本(文件扩展名无所谓,只要是纯文本文件即可)。注意该方法会直接将修改写入原文件,且不可撤销,使用前要注意备份原文件。
如要处理大量文本文件,请将 list.csv 和所有要处理的文本文档放在同一目录下,然后在该目录下创建脚本文件 replace.sh 并写入如下命令:
#!/bin/sh
for FILE in *.txt
do
L=1
E=`awk 'END {print NR}' list.csv`
while [ $L -le $E ]
do
A="`awk -F ',' -v L=$L 'NR==L {print $1}' list.csv`"
B="`awk -F ',' -v L=$L 'NR==L {print $2}' list.csv`"
sed -i "s/$A/$B/g" "$FILE"
unix2dos "$FILE"
L=$(($L+1))
done
done
到 CMD 中执行如下命令:
busybox ash ./replace.sh
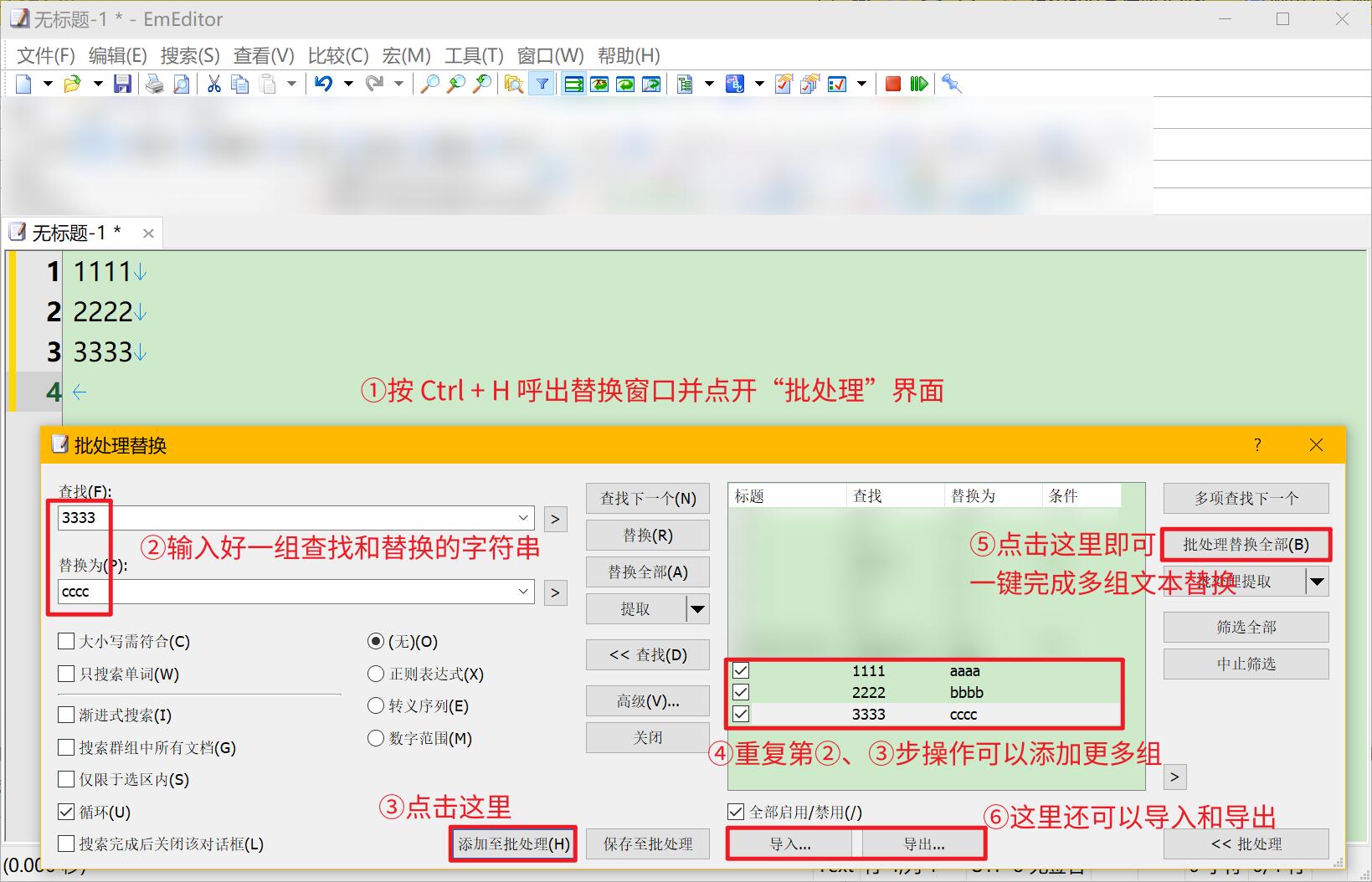
楼主可以考虑 EmEditor ,如下图操作:
不过我看了一下官网,
似乎只有专业版才有这个功能,
免费版没有……
所以你或许可以考虑找个专业版试一试,
然后再决定是否入正版~
https://zh-cn.emeditor.com/text-editor-features/history/emeditor-free/
这个是处理文件名吧,我需要处理的是文本文件里的内容
不错,就是替换表编辑起来略麻烦,留作备用 ![]()
感谢,就是我要得功能~
作一点补充说明:
sed 支持正则表达式,所以之前提到的对照表 list.csv 里面可以写入正则表达式,如在其中加入 [0-9],X 可以将文档中的所有阿拉伯数字替换为 X。awk 命令后的 -F 选项可以指定分隔符。如果替换列表中使用了其他分隔符,请作相应的替换。如:对照表中为 X=Y 的形式,则可将 awk -F ',' 替换为 awk -F '='。unix2dos $FILE 命令。参考资料:
呃,你试试下载别的下载站的看看?
我是在东坡下载站下载的
如果不用正则,直接使用字典替换文本,最通用的办法是上opencc
对啊,这倒是我从来没想到的用法,opencc 的确可以用来批量替换文本
以前只是用来简繁替换,果然还是我脑洞不够 ![]()
opencc 不适合小白——普通的繁简转换都不一定会用,更何况还要自定义词汇表。对小白来说,还是现成的GUI软件省心。
感谢各位大佬提醒,的确 opencc 也是一个很好的方法。
Windows 上安装 opencc 可以参考这篇文章:
Linux上的话,一般软件源里面应该就有。以Ubuntu为例:sudo apt install opencc。
然后,准备两个文件:
replace.jsondict.txt配置文件按如下格式书写:
{
"name": "Just for test",
"segmentation": {
"type": "mmseg",
"dict": {
"type": "text",
"file": "dict.txt"
}
},
"conversion_chain": [{
"dict": {
"type": "group",
"dicts": [{
"type": "text",
"file": "dict.txt"
}]
}
}]
}
其中,dict.txt 是我们一会儿要用到的对换表。
对换表文件 dict.txt 按如下格式书写:
原始字段[制表符]替换字段
注意 “原始字段” 和 “替换字段” 之间要用制表符分隔,不要用空格。
将 replace.json 和 dict.txt 放在同一文件夹下,然后打开命令行,执行转换命令:
opencc -i 输入文件 -o 输出文件 -c replace.json
其中,“输入文件” 和 “输出文件” 可以是同一文件,这样就可以直接修改输入文件的内容了。
如果是要处理大量文件,在WIndows系统上,可以写一个批处理文件:
@echo off
for %%i in (*.txt) do opencc -i "%%i" -o "%%i_output".txt -c replace.json
如果想直接修改原文件,则可使用这个批处理:
@echo off
for %%i in (*.txt) do opencc -i "%%i" -o "%%i" -c replace.json
opencc 还可以接收来自其他程序的标准输出,比如要对某程序的输出结果进行替换,可执行:
cat text.txt | opencc -c replace.json
说句题外话,如果只是要进行简繁转换,执行如下命令即可:
opencc -i 输入文件 -o 输出文件 -c s2topencc -i 输入文件 -o 输出文件 -c t2s更多功能可参考其项目主页:https://github.com/BYVoid/OpenCC/
真不错,又多一种方法。感谢感谢,网址收藏了 ![]()
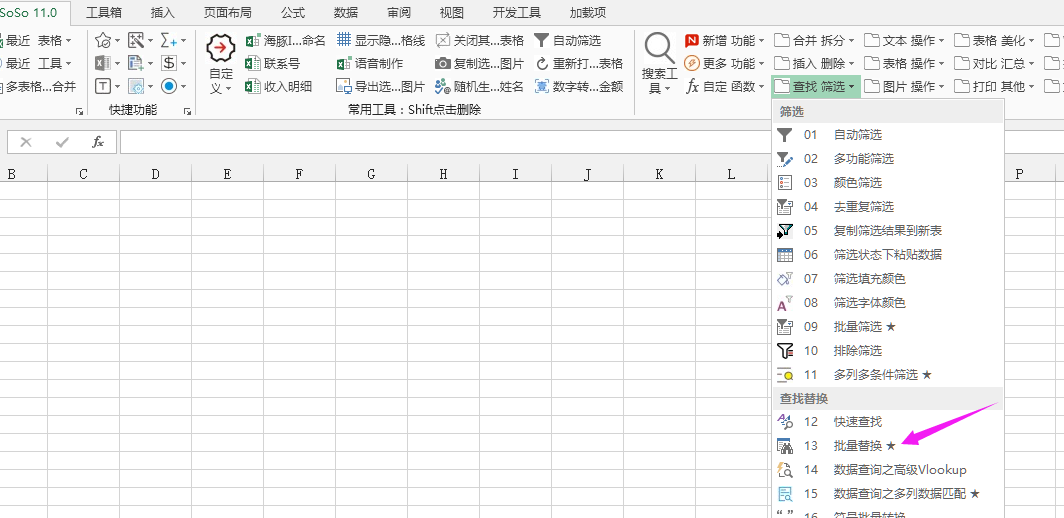
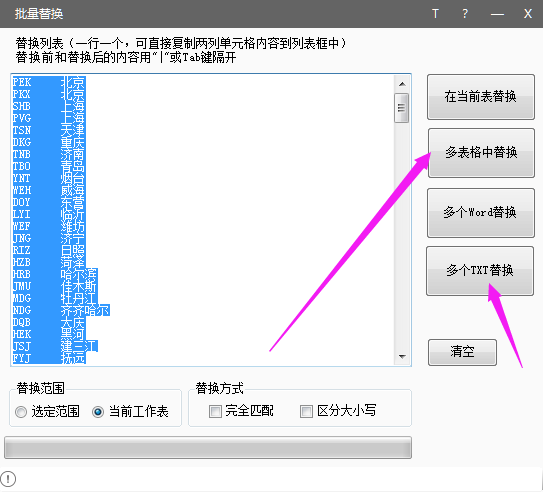
我的ABC软件工具箱 可以实现你需要的功能 批量替换不同规则的不同文档 都是可以的
最近才发现,其实这种替换表根本不用 awk。sed 是支持脚本模式的。
比如,要将文本文件中所有的 AAA 替换为 111,BBB 替换为 222,可将替换表按这种形式写好,并保存为 replace.sed:
s/AAA/111/g
s/BBB/222/g
其中,AAA、BBB、111、222 都是正则表达式或字符串(注意特殊字符要转义)
然后命令行运行
busybox sed -f replace.sed 输入文件 > 输出文件
即可。