CCR
1
如题,遇到了不同场景需要分别按姓氏笔画和姓名笔划排序……
但是大多程序不满足要求(指的就是贝特之姓氏笔画排序),例如姓“类”的,“闫”的,很多少见姓氏都找不到……
求救有没有程序能帮忙的,要大字库,哪怕不像思源那么广,好歹GBK标准得满足吧……
(实在不行我就自己出手……但我只会python,效率太低,排个本班没问题,数据量一大直接完蛋……rust三过门槛而不入……)
为防止有人不知道“姓名笔划”和“姓氏笔画”的区别,特此说明如下:
详请
姓名笔划和姓氏笔画(“画”与“划”通假,不影响):
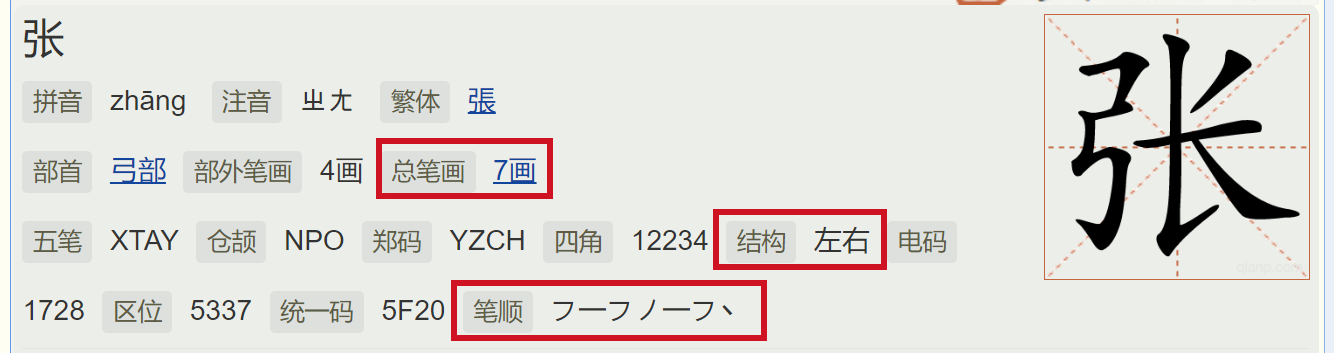
基础道理就是比较文字笔画数多少,少的在前;同样的比较笔画顺序,横前竖后,详细顺序此处不继续列举,可自行百度
姓名排序是按姓和名依次比较的;复姓只以首字视为姓,不以笔画相加作比较
姓氏排序也是一个道理,但姓氏排序时两个字的人,例如张三,视为3个字,中间的字为空格
举例:
张三四和张三
按姓氏排,为“张(空格)四”与“张三四”,张(空格)三在前
按姓名排,“张四”与“张三四”,“张三四”在前
具体参见:https://baijiahao.baidu.com/s?id=1718735201680082283
我觉得你已经把规则说的很清楚了。只差一个汉字和笔画数与笔画顺序的数据库。
这和你会什么编程语言似乎没有关系吧。
手动录入万个左右的姓氏,确定每一个汉字的笔画数。定义笔画顺序。
比如张姓和李姓都是7画,减少一点精度只定义前四个步骤,你可以定义横竖撇捺为1234,前者笔画为 1123,后者是1234。
按姓氏排序时,空格位顺序最优先。
按姓名排序时即按每个汉字的笔画数来排序。
只是得看你自己查找是否有人已经做了相关工作并开源出来。
zhongx
(zhongx)
3
这排序方法很复杂啊。
1、首先姓要单独拿出来解决,可简单定义为第一个字;可遇到复姓时,怎么准确知道前面哪两个字的组合为复姓?肯定会有漏网之鱼。(这才是重点)
2、先把 1 解决了,才能确定名的第一个字。
3、笔画数与笔顺反而是最好解决的,随便找个大字典,将词头与笔画数和笔顺提取出来就可以了,再将一(横)、丨(竖)、丿(撇)、丶(捺)、乛(折)定义为 12345 ,按数字就可以排序了。
CCR
4
找了,没有找到开源的处理方案……
另,语言还是很重要的,50多人没问题,变成500,50000效率一下就体现出来了,python终究还是差点意思,并且还得手动打包依赖库手动精简体积,去了别人电脑还要想想依赖怎么处理啥的……
c,rust什么的就没这些烦恼,效率嘎嘎高
自己用肯定是py好,发出来就不好了……
CCR
5
这反而简单,判断字数即可,2字一套方法,3字一套,3以上一套
复姓在这两套方法里面其实和“张王三四”这种名字一样,一视同仁处理的,复姓第二字会当做名的第一字处理……
我错了,确实姓氏笔画得按复姓算的……
CCR
6
还要看左右还是上下,感觉难以处理,例如“王冕”和“王晚”
王晚在前,因左右结构……
zhongx
(zhongx)
7
这样处理复姓,实在是太残暴了。 
同样在字典里提取,定义一下就好。
CCR
8
刚刚发现了一点点小问题,我要先做程序,好像要先学习数据库  要不然程序无从下手,以静态列表储存好像有点太奇怪了,并且也不好增添和修改,每次增添和修改都要重新发一版……
要不然程序无从下手,以静态列表储存好像有点太奇怪了,并且也不好增添和修改,每次增添和修改都要重新发一版……
其实也不一定要用数据库,这个最核心的就是汉字笔画信息表,做成一个字典结构,放一个单独的数据文件(格式随意,比如 JSON),程序从这个文件读取到内存数据结构。到时候更新也就更新这一个文件就成。
开源的话,只需要开源这一个数据文件。
教育部有专门的规范文件,直接去教育部官网下载就行,也有专门的排序软件,官方的各种名单,例如人大,政协这些就是用专门的软件处理的。
jack_w
14
馊主意:
使用在线服务,查完放入数据库,中国常用姓氏也不算很多,一次能查 12 个,百来次应该可以完成 
CCR
16
你这可太要命了啊,甚是不如把复姓单独挑出来以后,姓氏和名字分别用excel排序来的快啊
Jreen
(Jreen)
19
1 个赞
CCR
20
看到力,但是还是想自己写一个,不开源或者不是官方出的软件处理较敏感信息时总有顾虑